도커는 개발자라면 적어도 한번쯤은 들어봤을 법한 기술 중 하나입니다. 많은 사람들이 도커를 사용하고 있다는 사실은 더이상 특별한 이야기가 아니며, 취업공고에도 도커와 같은 컨테이너 기반 기술에 대한 경험이 명시되어 있을 정도로 말입니다. 특히나 요즘은 대부분의 인프라가 클라우드로 옮겨가면서 쿠버네티스 기반으로 이루어진 마이크로서비스 아키텍처(MSA)들을 표방하고 있기때문에 그 근간이 되던 컨테이너 기술과 그 컨테이너 기술의 대표주자인 도커는 자연스럽게 상식의 영역에 가까워지고 있는 듯 합니다.
이쯤되면 도커는 무엇이길래 인기가 이렇게 많고 왜 사람들이 열광할까라는 의문 혹은 호기심이 드는 건 아주 자연스러운 흐름일겁니다. 그래서 저 또한 포스팅을 통해 도커가 무엇인지부터 도커를 왜 써야하는지에 대한 이야기들을 공부하고 적어보려하는 것이구요. 이번 포스팅은 도커에 대한 이야기 그 첫번째 시간으로써 도커가 어떻게 시작되었고 어떠한 메커니즘을 가지고 있는지에 대해 알아볼 겁니다.
도커의 시작
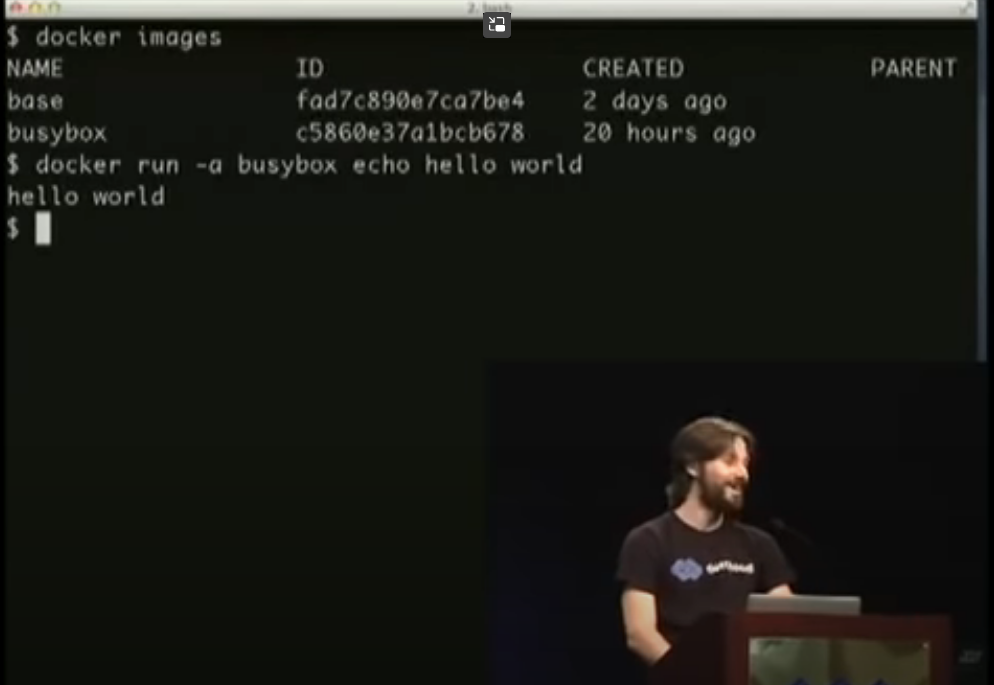
도커는 벌써 등장한지 10년이 되가는 꽤 오래된 기술입니다. 솔로몬 하익스(Solomon Hykes)는 2013년 파이콘(Pycon) US에서 리눅스 컨테이너의 미래(The future of Linux Container)라는 세션에서 도커를 처음 소개했습니다. 앞선 링크를 따라 영상을 보면 단 몇초만에 새로운 운영체제를 생성하고 그 운영체제 안에서 Helloworld를 출력하는 모습을 볼 수 있는데 이것이 도커의 강력함을 보여주는 가장 대표적인 예시입니다.
이 발표 이후 도커의 인기는 폭발적으로 증가했습니다. 솔로몬 하익스가 dotCloud였던 회사명을 아예 Docker Inc로 바꿀 정도로말이죠. 2014년에는 도커콘을 열어 도커 1.0버전을 발표했고 2022년 12월 기준으로 20.10버전이 가장 최신의 버전입니다. 그리고 현재의 도커는 고 언어(Go Language)로 개발되고 있습니다.
도커는 무엇인가?

가볍게 도커의 시작에 대해 알아봤고 이제는 본격적으로 도커에 대한 이야기를 해볼 차례입니다. 도커를 한 문장으로 정의하자면 ‘컨테이너 기반의 가상화 플랫폼’이라고 할 수 있습니다.
컨테이너 하면 위의 그림처럼 항구에 나열되어 있는 컨테이너들이 생각이 납니다. 영화나 드라마같은 데서도 많이 볼 수 있는 장면이죠. 컨테이너의 특징을 생각해보면 규격화되어있고 각각은 독립된 공간입니다. 뭐든 컨테이너 규격에만 맞다면 집어넣을 수 있고 컨테이너는 컨테이너선에 실려서든 지게차나 트레일러 등에 실려서든 옮겨 다닐 수 있습니다. 어떤 운송수단이든 컨테이너만 실을 수 있다면 어디든 갈 수 있는 것이죠.
우리가 서버에서 이야기하는 컨테이너도 이와 다르지 않습니다. 다양한 프로그램, 실행환경 등을 컨테이너로 추상화하고 동일한 인터페이스를 제공하여 프로그램의 배포 및 관리를 단순하게 해줍니다. 웹서버, Django나 FastAPI같은 WAS, 하둡이나 스파크 같은 빅데이터 프레임워크, MySQL 등의 데이터베이스, Kafka 등의 메세지 큐 뭐든지 컨테이너로 추상화할 수 있고 내 컴퓨터든, 아니면 퍼블릭 클라우드든 어디에서나 실행할 수 있습니다.
컨테이너

조금 더 컨테이너 개념에 대해서 알아 보겠습니다.
컨테이너는 리눅스 시스템 기능인 네임스페이스(Namespace)와 Cgroup을 기반으로 만들어집니다.
네임스페이스는 프로세스를 독립시켜주는 가상화 기술입니다. 같은 커널위에서 돌긴하지만 네임스페이스로 만들어진 프로세스는 다른 프로세스들과는 독립적입니다. 네임스페이스로 격리된 공간을 만들고 나면 필요한게 cgroup이라는 기술입니다. cgroup은 control group의 약자로 CPU, RAM, HDD 등의 하드웨어 자원을 배분하는 기능을 수행합니다. 이를 통해 주어진 리소스를 효율적으로 사용할 수 있고 컨테이너에 올라가는 어플리케이션의 필요에 따라 추가적인 리소스할당이 가능한 유연성을 가질 수 도 있습니다.
이제 이렇게 만들어진 컨테이너를 좀 더 특별히 LXC(Linux Container)라고 부릅니다. 이 독립된 컨테이너에는 사용자가 원하는 기능을 올릴 수 가 있습니다. Java, python, hadoop, spark, nodejs, mysql 등 뭐든 말이죠.
컨테이너 VS 가상머신
이런 컨테이너 기술과 비슷한 것이 VMware나 KVM과 같은 가상머신입니다. 둘다 가상화 기술의 일종이라는 것은 같지만 또 이 둘이 완전히 같은가 하면 엄연히 다릅니다.
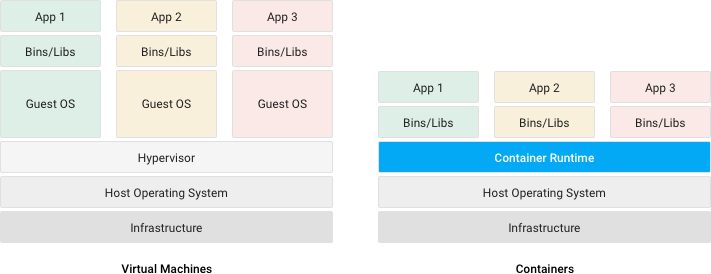
VMware와 같은 가상머신은 호스트 OS 위에 게스트 OS 전체를 가상화하여 사용하는 방식입니다. 이를 통해 리눅스에서 윈도우를 돌리는 것과 같이 여러가지 OS를 가상화 할 수 있고 비교적 사용법도 간단합니다. 그러나 OS는 상당히 무겁고 가상머신이 필요한 사람들이 사실 모든 OS의 기능을 필요로하지 않는 다는 것을 생각하면 상당히 비효율적이기도 합니다. 게다가 Virtual box나 VMware를 사용해서 가상머신을 만들어 보신분들은 알겠지만 리소스를 상당히 잡아먹기 때문에 느립니다. 그래서 이러한 가상머신이 보통의 운영환경에서 사용할 수 없었던 단점을 개선하기 위해 프로세스를 격리하는 방식이 등장하는데 이게 바로 컨테이너라는 기술입니다.
위의 그림에서 보면 컨테이너는 게스트 OS를 필요로 하지 않고 어플리케이션이 올라가 있는 것을 확인 할 수 있습니다. 이는 컨테이너가 OS위에서 실행되긴 하지만 사용자가 사용하려는 어플리케이션이 작동될 정도의 적당한 리소스를 컨테이너에 할당한다는 것을 의미합니다. 따라서 컨테이너에서 실행되는 프로세스의 커널크기를 보면 보통 수십~수백 MB 수준이고 부팅과 종료 또한 매우 빠릅니다. 즉, 성능적으로 거의 손실이 거의 없습니다.
실제 하나의 서버에 여러개의 컨테이너를 실행시켜보면 서로 영향을 미치지 않고 독립적으로 시행되기 때문에 가벼운 가상머신을 사용하는 듯한 느낌을 받습니다. 그리고 실행중인 컨테이너에 접속하여 다양한 리눅스 명령어를 사용할 수 있고 apt나 yum 등으로 패키지 설치도 가능합니다. 즉, 우리가 OS환경에서 사용할 수 있는 모든 것을 할 수 있는 것 입니다. 게다가 새로운 컨테이너를 만드는 데는 고작 1~2초의 시간이면 충분합니다. 가상머신과는 비교할 수 없을 정도로 빠르죠.
리눅스 컨테이너와 도커
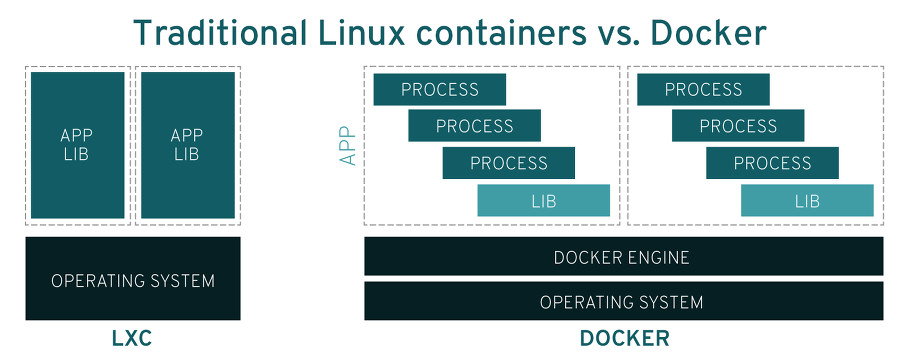
그럼 도커는 ‘이 컨테이너 기술을 만든 최초의 기업인가’라고 한다면 아닙니다. 도커가 등장하기 이전에도 리눅스에서 프로세스를 격리하는 방법은 많았습니다. 우리가 앞서 이야기했던 LXC부터 시작해서 jail, solaris zones, Imctfy 등의 기술이 있었습니다. 도커는 이 중 LXC를 기반으로해서 만들어진 도구에 불과합니다.
그러나 현 시점의 도커는 기존의 LXC와의 종속성에서 벗어났습니다. 초기 도커는 LXC처럼 컨테이너를 도커는 컨테이너를 구동하는 작업에 초점을 뒀지만 이제 도커는 그 이상의 것들을 제공하기 때문입니다. 대표적으로 도커는 컨테이너의 생성 및 구축 뿐만아니라 가상머신의 스냅샷과 같은 컨테이너의 이미지화를 지원합니다. 뒤이은 단락에서 추가로 설명하겠지만 이미지의 사용으로 컨테이너를 훨씬 쉽게 배포가 가능하고 재사용도 용이하며 버전의 관리도 쉬워집니다. 추가로 LXC 대신 자체적으로 개발한 libcontainer 기술을 사용하기 시작한 것도 LXC와 많은 부분이 달라지게 된 원인이기도 합니다.
이미지
도커에 있어 가장 중요한 개념은 컨테이너일겁니다. 그리고 이와 동등하게 중요한 개념이 바로 이미지입니다. 이미지는 가상머신에서 사용하는 스냅샷과 같은 개념입니다.
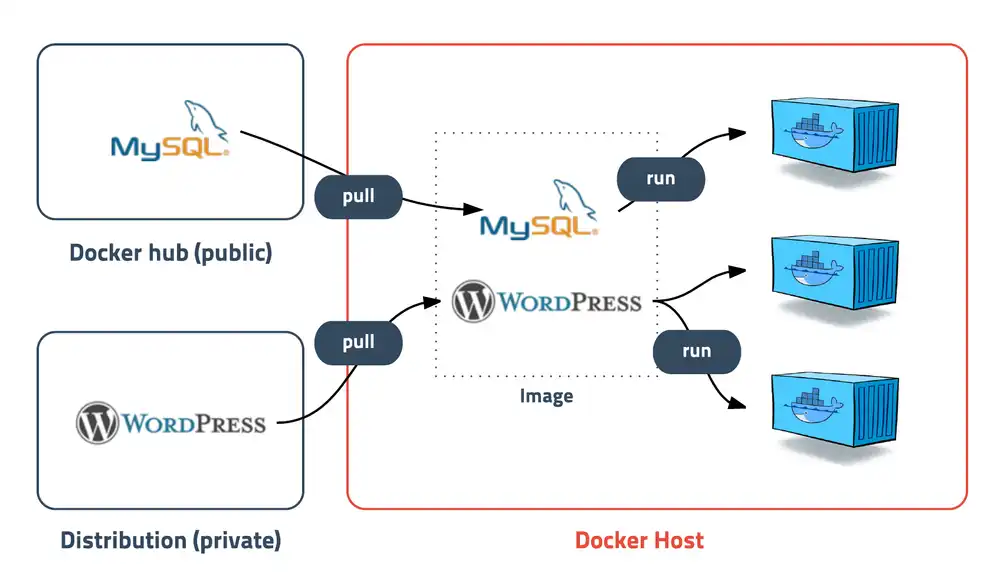
이미지는 컨테이너 실행에 필요한 파일과 설정값들을 포함하고 있으며 상태값을 가지고 있지 않고 변하지 않습니다. 컨테이너는 이미지를 실행한 상태라고 볼 수 있고 추가되거나 변하는 값은 이미지가 아닌 컨테이너에 저장되는 것입니다. 같은 이미지에서 여러개의 컨테이너를 생성할 수 있고 컨테이너의 상태가 바뀌거나 삭제되더라도 이미지는 변하지 않고 그대로 남아 있습니다.
아주 쉽게 비유하면 이미지는 일종의 레시피책을 한권 가지고 있는 것과 같습니다. 레시피 책을 보더라도 그걸 요리하는 저는 다양한 베리에이션을 줄 수 있습니다. 내가 좀 짜게 먹으면 소금 한꼬집 추가할 수 있고 고소한 참기름 한바퀴 더 돌릴 수 있다는 것입니다. 아무리 다양한 베리에이션을 줘도 레시피 책은 불변합니다. 내가 행동하는 데로 책 내용이 바뀌는건 해리포터에서나 볼 수 있는 장면이니까요.
아무튼 이미지는 말그대로 컨테이너를 실행하기 위한 모든 것을 가지고 있습니다. 그저 새로운 서버가 추가되면 미리 만들어 둔 이미지를 다운받고 컨테이너를 생성하기만 하면 됩니다. 그리고 이미지만 있다면 이를 사용해서 수많은 컨테이너를 찍어낼 수도 있으니 아주 편리합니다.
도커이미지는 자신이 직접 만들어 Docker hub에 등록하거나 github을 통해 배포할 수 도 있습니다. 또한 Docker hub에는 도커에서 공식적으로 만들거나 지정한 이미지들이 있어 이를 간단한 명령어(docker pull)로 가져다 쓸 수도 있습니다.
정리
결국 도커는 기존 가상머신을 사용할 때보다 가볍고 빠르며 유연합니다. 이러한 점들이 도커의 장점이 될 수 있지만 컨테이너라는 기술이 훨씬 전부터 존재했었는데 왜 도커가 갑자기 2013년에 각광을 받았을까 그리고 왜 이젠 도커가 개발자에겐 당연한 것처럼 받아들여지고 있을까하면 아직도 모르겠습니다. 그래서 다음 도커에 대한 포스팅은 ‘왜 도커는 이렇게 인기가 많아졌을까?’ 그리고 ‘왜 도커를 써야하는가?’하는 부분에 초점을 맞춰서 작성할 계획입니다.
추가로 여담이지만 이번 포스팅을 통해 HDFS에서 네임노드의 네임스페이스 부분이 좀 명확해 졌다는 수확이 있습니다. 사실 네임스페이스가 계층시스템을 갖고 있고 거기에 블록정보들이 들어가 있고 이걸 fsimage를 만들고하는게 직관적으로 다가오진 않았는데 이번 포스팅을 작성하기 위해 도커를 사용해보니까 좀 알것도 같습니다. 컨테이너 안에 들어가서 ls명령어도 칠수 있고 mkdir 명령어로 디렉토리도 생성가능하고 commit 해서 컨테이너를 이미지화 시킬수도 있고 이 과정을 겪어보니 ‘아 HDFS의 네임스페이스도 이런 느낌이겠구나’ 하는 생각이 들었습니다. 확실히 이론도 중요하지만 실사용이 이렇게 중요하다 라는 생각이 새삼 든다는 말로 갈무리하며 이 포스팅을 마치겠습니다.