최근들어 난해한 공부들을 많이하게 되는 것같습니다.
EC 하나 공부해보려고 시작한게 RAID에서 이젠 Parity까지 왔습니다. 평범하게 이해할만한 내용은 또 아니니 이렇게 포스팅을 작성하고 아주 블로그가 풍년이에요.
솔직히 적당히 넘어가도 되는거 같긴한데 그럼에도 이걸 좀 공부해서 이해해보려는건 기본 CS지식에 해당한다고 해서입니다. 사실 요즘 여러 공부를 하면서 느끼는 거지만, 확실히 대부분의 레퍼런스들은 어느정도 CS지식이 깔려있다는 전제하에서 전개되는 내용들이 좀 많다고 느끼거든요. 그래서 이런 상황이 있을때 하나라도 좀 알아둬야 나중에 고생안할것 같아서 정리해두려합니다.
이걸 끝내고 다시 RAID와 EC까지 하려면 한참 남은것 같아서 어지럽긴한데 그래도 여기까지 왔는데 뭐 어쩌겠습니까 해내야죠.
Parity란?
컴퓨터 공학에서 패리티(Parity)는 기존의 정보와 동등한 상태인지를 확인할 때 사용됩니다. 가장 대표적으로는 오류가 났는지 검사하기위해서 사용이 되죠.
패리티는 보통 패리티 비트라는 방식으로 구현이 됩니다. 패리티 비트는 기존의 데이터와 같은지 확인하기 위해서 추가하는 비트를 말합니다.
패리티 비트는 홀수 패리티 비트와 짝수 패리티 비트로 나뉘는데, 짝수 패리티 비트는 0과 1중 1이 짝수게 되도록 비트를 추가하는 것을 의미하고 홀수 패리티 비트는 0과 1중 1이 홀수가 되도록 비트를 추가하는 것입니다.
좀 더 직관적으로 이해해보기 위해서 아래 그림을 보면서 하나씩 이해해보도록 하죠.
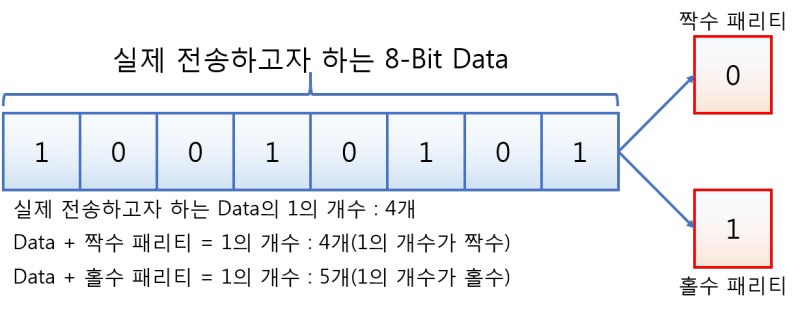
패리티 비트의 값을 결정하는 요소는 원본 데이터의 비트들중 1의 값이 몇개가 있느냐 입니다. 위의 그림에서는 총 4개의 비트가 1이라는 값을 갖고있습니다.
먼저 짝수 패리티 비트를 사용한다면, 패리티 비트는 0의 값을 갖습니다. 왜냐하면 1의 개수가 짝수니까요. 패리티 값이 1을 가져버리면 1의 개수가 5개로 홀수가 되니 규칙에 어긋나버립니다. 따라서 패티리 비트가 0의 값을 가짐으로서 1의 개수가 짝수로 유지되도록 하는 것이죠. 결과적으로 원본 데이터와 짝수 패리티가 짝수가 되도록하면 이때의 패리티 비트는 짝수 패리티 비트라고 할 수 있습니다.
반면 같은 논리로 홀수 패리티 비트를 사용한다면, 1의 개수가 짝수이니 패리티 비트는 1의 값을 갖습니다. 이를 통해 패리티 비트를 포함한 데이터의 1의 개수가 홀수가 되기 때문이죠.
오류 검사
앞의 내용만 보면 패리티비트가 이런거구나 하는정도만 알지 뭐 어떻게 동등한지 판별하고 오류를 검사한다는 건가 싶은게 사실입니다.
도대체 어떻게 패리티 비트로 기존의 정보와 동등한 상태인지 확인할 수 있는걸까요?

이를 이해하기 위해 홀수 패러티 비트가 사용된 데이터를 보도록 하죠.
지금은 데이터가 정상적인 상태를 유지하고 있습니다. 패러티 비트까지 포함해서 5개의 1이 있으니까요.
그럼 여기서 1이였던 비트 중 하나가 0이 되었다고 해보죠.

원래는 1 0 0 1 0 1 0 1인 원본 데이터가 1 0 0 1 0 0 0 1이 되면서 1의 개수가 4개로 짝수가 되어버렸습니다.
그럼 원래 홀수 패리티 비트 방식을 사용했기 때문에 1의 개수가 홀수여야하는데 4개로 짝수가 되었으니 ‘1개의 비트가 변했구나’라는 사실을 알게 되는 것이죠.
즉, 패리티 비트를 통해 데이터가 이전과 같지 않은 상태가 되었다는 사실을 인지하여 오류를 검출할 수 있게 되는 것입니다.
Parity를 통한 데이터 복구
패리티 비트는 시리얼 통신 같은 데이터 전송 때 오류를 검사하는 용도로 주로 사용되는게 맞습니다.
그런데 RAID에서는 패리티 블록를 만들어서 데이터의 중복성을 보장하고 이를 통해 유실되거나 손상된 데이터의 복구까지 가능합니다.
기껏 패리티 비트를 공부했더니 뭔 패리티블록이고 데이터복구냐라고하면 할말은 없지만, 어찌됐든 중요한건 패리티가 오류를 감지할 뿐만 아니라 데이터 복구에도 사용될 수 있다는 사실입니다.
하지만 여기서 의문이 하나 생기죠. 지금 앞선 그림들을 보면서 아 1이 짝수구나 홀수구나 하는건 사람이 하는 것이고 컴퓨터는 도대체 어떻게 이 계산을 수행할 것이냐에 대한 의문이 말이죠.
여기서 사용되는 것이 XOR(Exclusive OR)이라는 알고리즘입니다.
XOR은 서로 다르면 1 같으면 0입니다. 그냥 앞서 본 그림에서 데이터 비트를 차례대로 XOR연산을 하면 마지막에 나오는 수가 짝수 패리티 비트입니다. 근데 우리는 홀수 패리티비트를 사용했으니 홀수 패리티 비트를 구할려면 마지막에 나오는 수를 NOT 처리만 해주면 됩니다.
이해를 쉽게 하기위해 1 0 0 1 4bit 짜리 원본데이터에 홀수 패리티 비트를 사용한 예를 들어보죠.
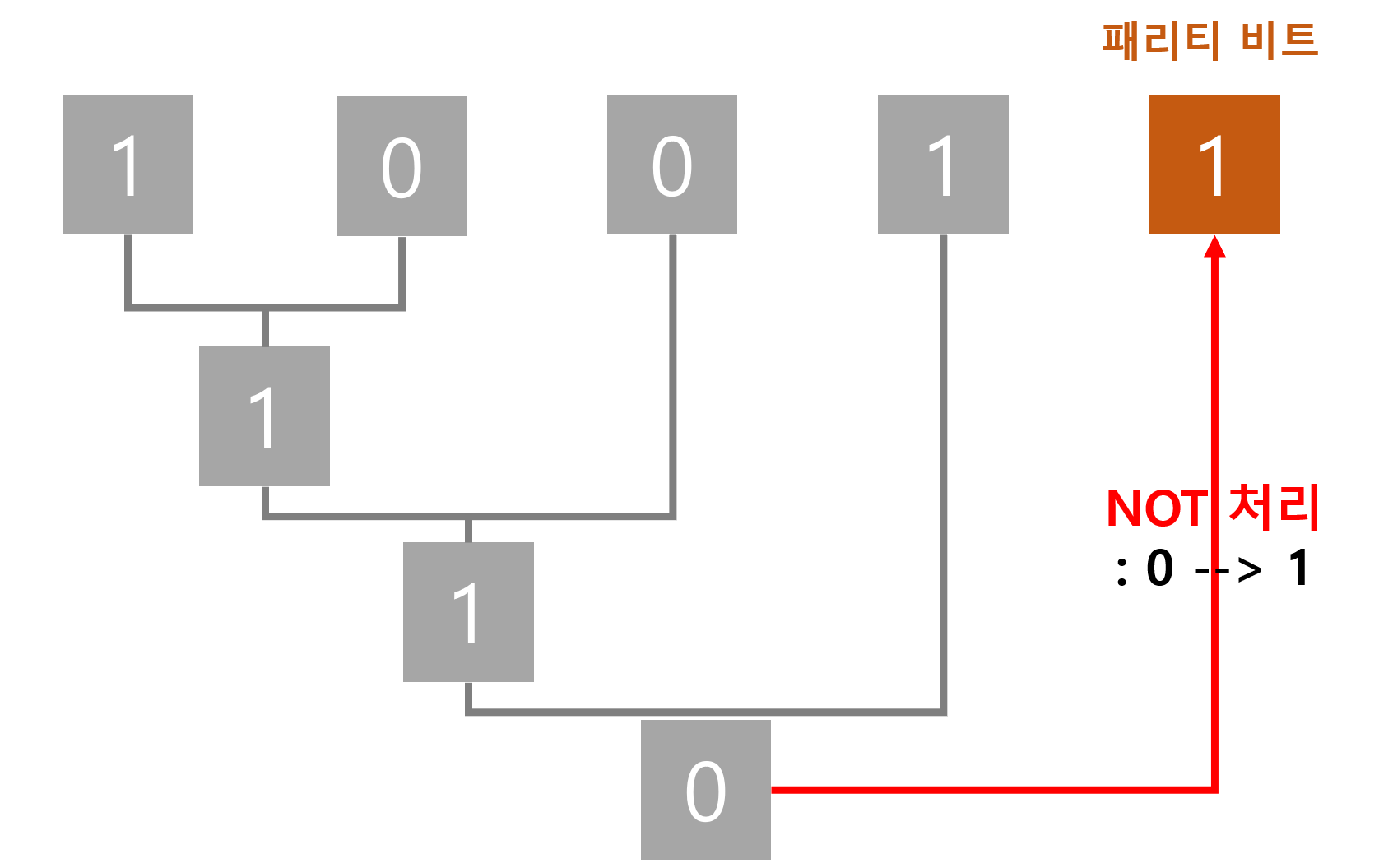
컴퓨터는 원본 데이터가 주어지면 XOR 알고리즘을 수행해서 패리티 비트를 구합니다.
우선 앞의 두 비트를 비교해서 서로 다르니 1입니다. 그리고 세 번째 비트와 비교해서 다르니 1입니다. 마지막 4번째 비트와 비교해서 서로 같으니 0입니다.
홀수 패리티 비트를 사용했기 때문에 NOT 처리를 통해 0을 1로 바꾼후 홀수 패리티 비트를 생성합니다. XOR을 수행한 후 NOT 처리를 한 것을 패리티 비트로 만들어 준 것이죠.
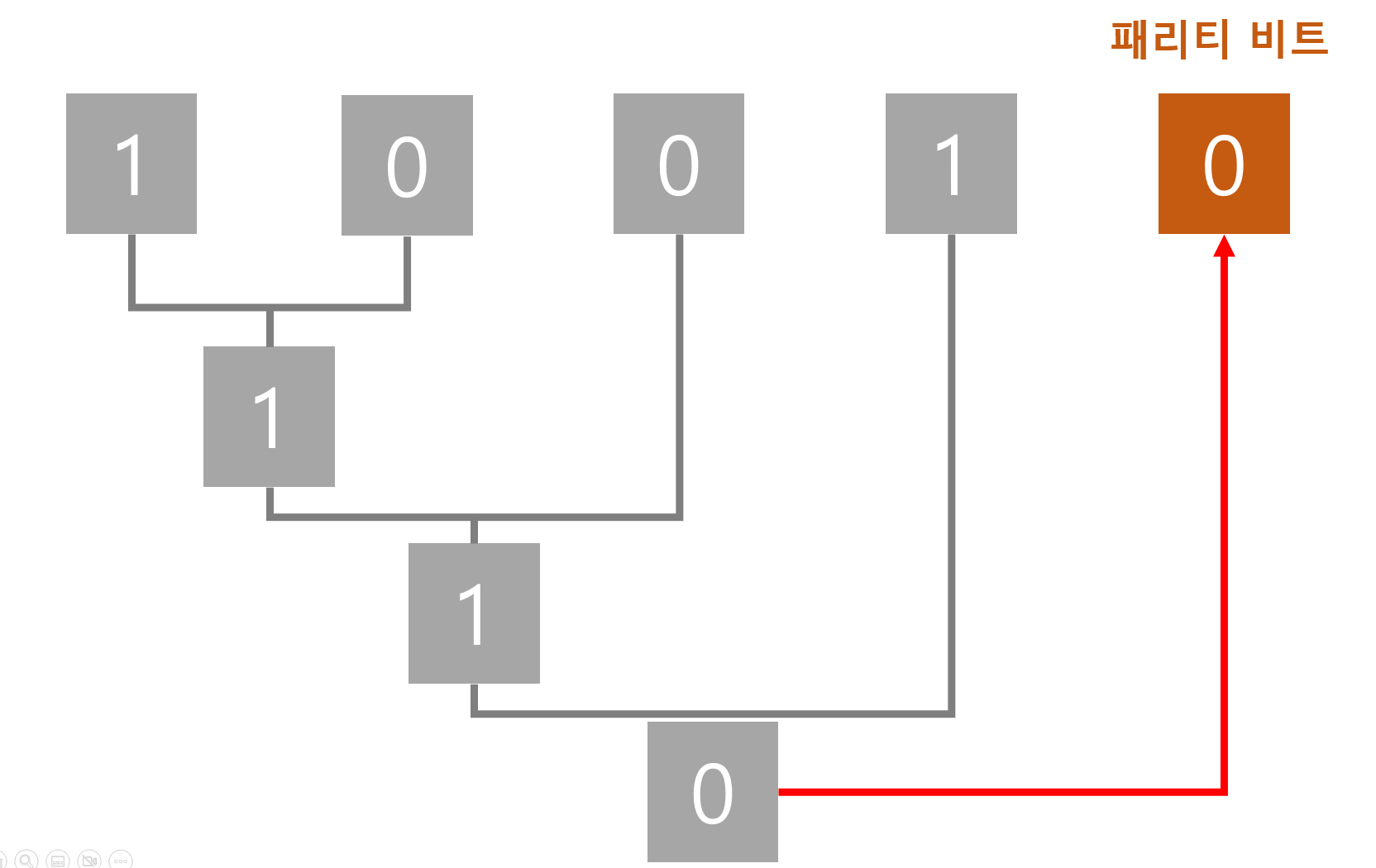
반대로 짝수 패리티 비트를 사용한다면, XOR연산 후에, NOT처리 없이 그대로 패리티 비트를 생성해주면 됩니다.
결과적으로 XOR 연산이 이루어진 값이 0이나 1이 나오는데, 0이면 원본 데이터의 1의 개수가 짝수임을 의미하고 1이면 홀수임을 의미하는 것이죠. 그래서 홀수 패리티 비트를 쓸것이냐 짝수 패리티 비트를 쓸것이냐에 따라 패리티 비트를 만들 때 그대로 사용할 것인지 아니면 NOT처리를 할 것인지가 XOR 알고리즘 자체에서 계산이 이루어지게 되는 것입니다.
블록 단위의 패리티 비트
RAID 3부터 바이트 단위의 패리티 비트를 사용합니다. 이후 RAID 4부터는 볼록 단위의 패리티 비트가 사용되구요.
그래서 패리티 블록에 대해 이해를 하려면 바이트 단위의 패리티 비트가 어떻게 작동하는지부터 공부해야합니다.
RAID 3에서는 1024바이터로 데이터를 나눠서 저장하는데 이건 현실적으로 예를 들기 힘드니 2바이트 짜리로 한번 이해를 해보록 하죠.
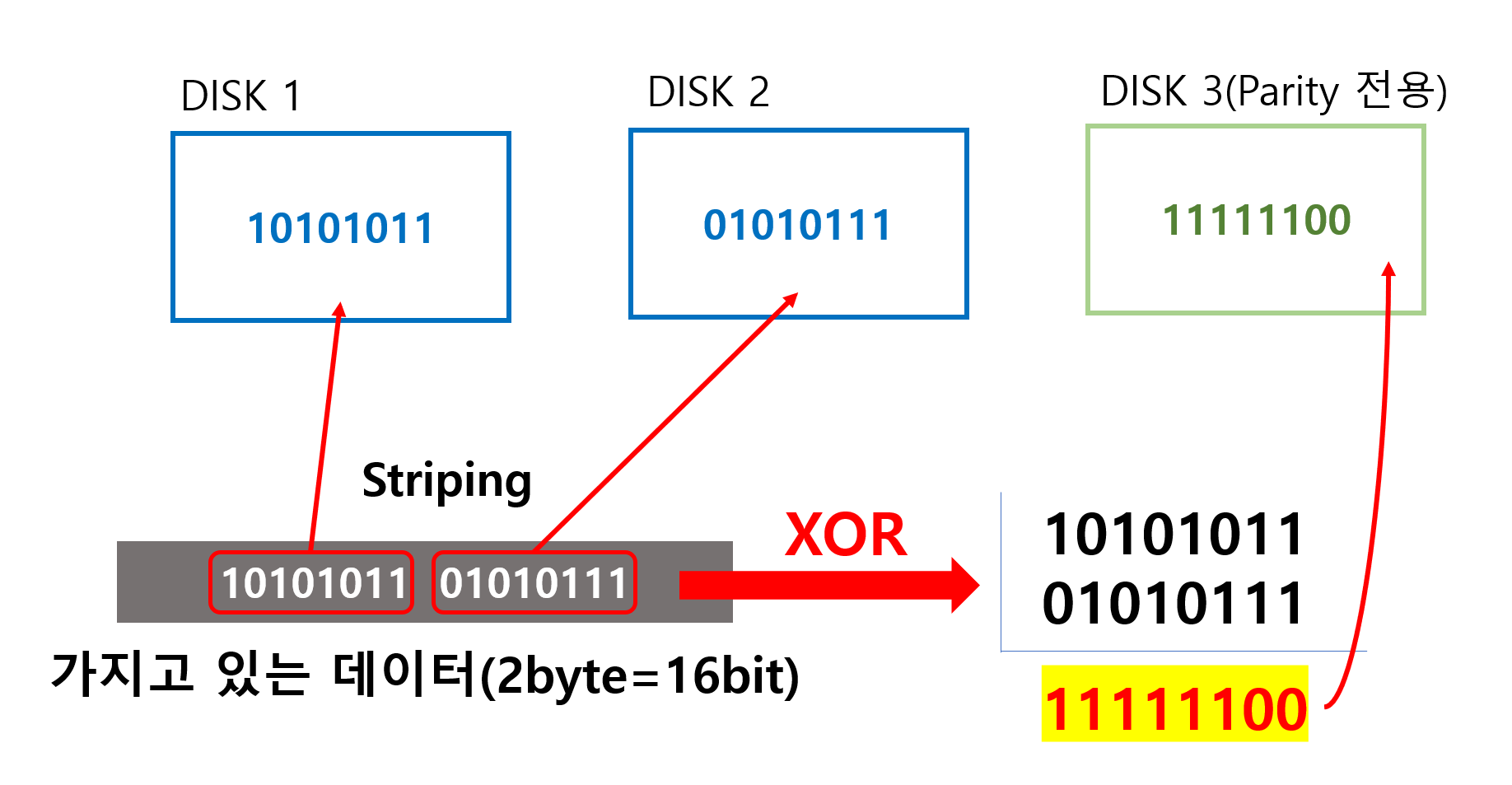
우선 디스크는 총 세개가 있고 그 중 두개는 데이터가 바이트 단위로 나눠진 뒤 저장될 디스크고 나머지 하나만 패리티 비트용 디스크입니다. 각 디스크에는 1바이트 씩 저장이 되고 이번에 패리티 비트는 짝수 패리티 비트를 사용한다고 하겠습니다.
16비트의 데이터는 스트라이핑이라는 과정을 통해 8비트씩 나눠지고 각 디스크에 저장이 될 겁니다. 이때 패리티 비트를 만들기 위한 XOR 연산이 같이 이루어집니다.
두 8비트짜리 데이터를 가지고 XOR 연산이 이루어지는 모습을 보면, 앞에서부터 차례대로 두 데이터가 같은 비트인지 아닌지를 판별하게 됩니다.
그렇게 나온 1 1 1 1 1 1 0 0이 짝수 패리티 비트가 되고 이는 디스크 3에 저장이 됩니다.
이렇게 저장이 될 경우에, 이 세개중에 하나의 디스크의 정보에 손상이 발생하더라도 남은 디스크의 데이터들을 사용해서 손상된 디스크를 복구 할 수 있습니다.
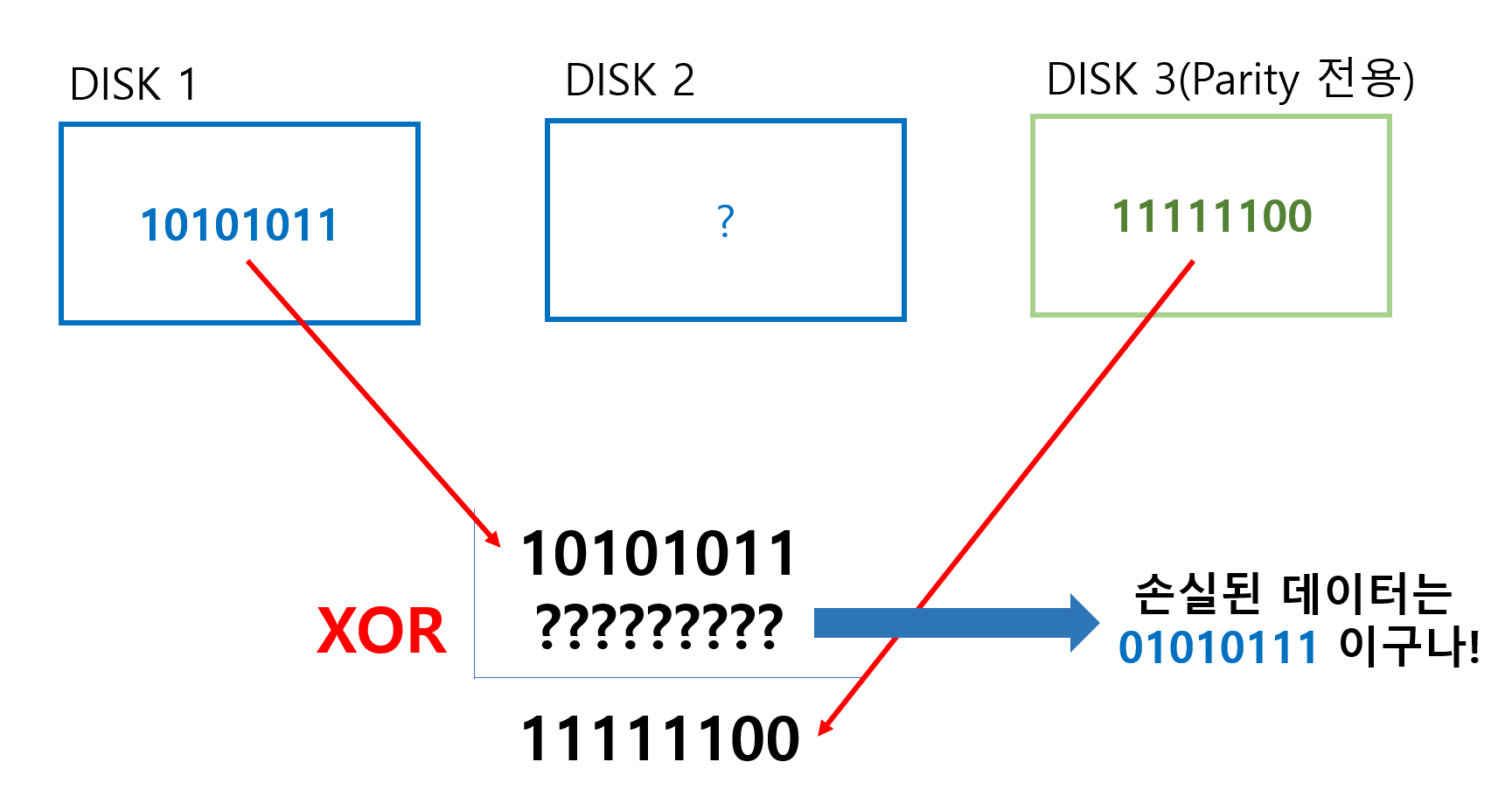
하지만, XOR 알고리즘의 특성 상 오직 단 하나의 디스크만 복구 가능합니다. 0과 1로 데이터가 변했는지를 체크하기 때문에 2개이상의 디스크가 손상이 나버리면 판별이 불가능하다는 것이죠.
따라서 이 RAID 3가 가지는 Fault tolerance는 디스크 1개인 것입니다. 이건 디스크의 개수가 매우 많아진다고 할지라도 마찬가지 입니다.
그리고 패리티 비트를 사용하는 RAID는 최소 세 개이상의 디스크를 사용해야합니다. 이유는 단순합니다. 패리티 비트를 저장하는 디스크가 별도로 있기 때문에 2개의 디스크를 사용하는 경우에는 데이터용 디스크 1개, 패리티용 디스크 1개일텐데 그러면 RAID1이랑 별 차이가 없기 때문이죠.
이어서 RAID 4에 대해서도 이야기를 해보죠. 사실 RAID3와 그냥 완전히 똑같습니다. 다만 한가지 다른건 RAID3는 앞서 이야기했듯 바이트 단위로 데이터를 쪼개지만, RAID4는 블록단위로 데이터를 쪼갭니다.
바이트 단위랑 블록 단위는 말그대로 파일 쪼개지는 단위에 대한 설명인데 블록단위는 보통 HDFS를 기준으로 생각해보면, 64MB ~ 256MB정도고 1KB가 1024바이트니까 꽤나 큰 차이가 있긴합니다. 그래도 패리티가 생성되는 과정은 똑같습니다.
그런데 RAID 3와 4 큰 단점이 있어서 이제는 거의 안쓰이는 추세입니다. 이 단점은 별도의 디스크에 패리티 정보를 저장해야한다는 것에서 출발합니다.
데이터들은 분할된 후에 여러개의 디스크로 나누어져서 저장이 되는데 반해, 패리티비트는 하나의 디스크에만 저장이 되기때문에 병목현상이 발생합니다. 여기서 파생되는 문제로 다른 디스크들에 비해 빈번한 I/O작업으로 인해 패리티 디스크의 수명이 빠르게 줄어든다는 것도 있습니다. 게다가 데이터를 읽어 올때도 프로그램적으로 패리티 비트가 있는 디스크는 제외해야하기 때문에 읽기 속도에서도 성능 저하가 발생합니다.
이후 이러한 단점들을 보완한 RAID5가 등장하면서 RAID 3, 4는 지금은 완전히 사용을 안하게 된 것입니다.
RIAD5
이왕 여기까지 온거 RAID 5도 한번보도록 하겠습니다.
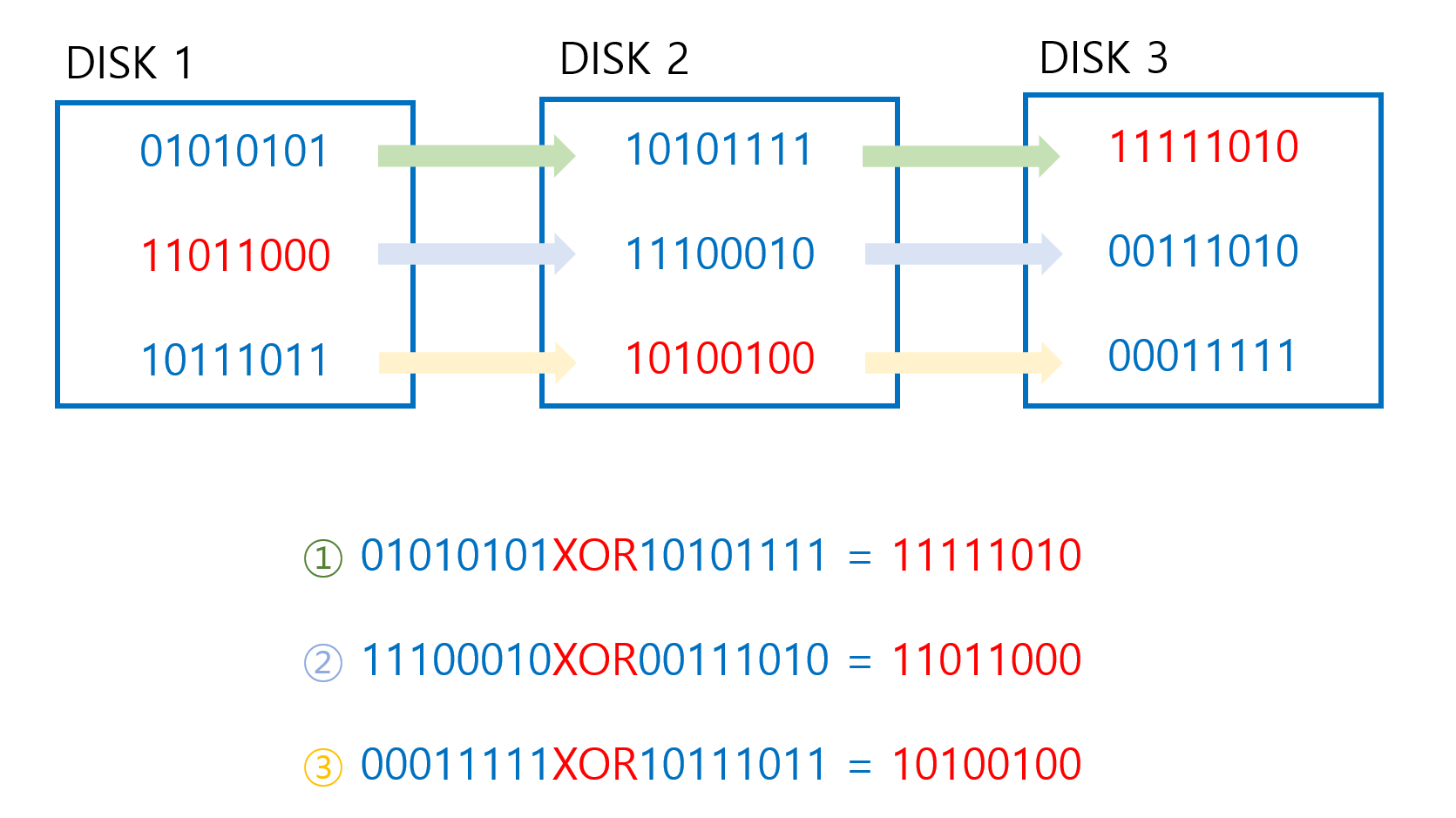
RAID 5는 패리티 정보의 저장을 전담하는 디스크를 없애고 패리티 정보를 모든 디스크에 분산 저장합니다. 스트라이핑 과정으로 데이터를 블록단위로 나누고 XOR 연산을 통해 패리티 블록을 생성한 후, 이를 순차적으로 디스크에 넣습니다. 이때 중요한 것은 패리티 블록은 디스크를 번갈아가면서 저장한다는 것입니다.
이를 통해 패리티 디스크를 제외하고도 RAID를 구성할 수 있게 되었고, 병목현상도 없으니 읽기 쓰기 성능에서 개선도 이루어집니다. 그러면서도 디스크 중 하나가 고장 나더라도 복구할 수 있는 fault tolerance를 가지게 되니 RAID 3,4보다 완벽하게 상위 호환이 되게 됩니다.
다만 RAID 5는 역시 모든 디스크에 패리티 블록이 저장되어야 하기 때문에 실질적으로 데이터를 저장하기 위해 사용되는 디스크는 RAID 3, 4와 같은 전체 디스크의 수 - 1입니다. 즉 원본 데이터 외에 패리티 저장을 위한 추가 저장공간이 필요해서 저장 효율이 떨어진다는 단점이 있습니다.
추가로 RAID 6도 있는데 패리티 블록이 1개인 RAID5와 다르게 패리티 블록이 2개가 됩니다.