개요
최근 데이터 엔지니어링은 무엇인가라는 고민들을 해봤습니다. 취업준비를 하다보니 단순 빅데이터 오픈소스들을 활용하는 것만큼이나 클라우드의 여러 fully managed service들을 통한 파이프라인들을 만드는 경험 또한 필요하다는 생각이 들었기 때문입니다.
물론 현재의 데이터 엔지니어는 데이터 파이프라인을 만드는 사람입니다. 그런데 업계 사람들이 작성한 글이나 유튜브 영상들을 보면 그보다는 훨씬더 다양한 일을 하는 서포터라고 이야기를 많이 합니다. 개발/도메인/파이프라인/클라우드 등 포괄적인 영역에 데이터 엔지니어의 역량이 발휘된다는 것이죠.
일종의 해결사이며 나아가면 마술사 같은 것으로 비유되기도 합니다. 사실 이런것도 할 수 있나라고 할 정도의 포괄적인 범위를 다루는 것이 데이터 분야의 매력일지도 모르겠습니다.
어쨋든 저는 오픈소스로 데이터 파이프라인을 만드는 경험을 쌓았을 뿐입니다. 그런데 제가 타겟으로 하는 대부분의 스타트업들 그리고 고유의 레거시를 가진 대기업이라고 하더라도 AI/ML분야는 빠른 속도로 클라우드로의 전환이 이루어지는 것이 현실입니다. 이러한 현상은 취업공고들에서도 쉽게 찾아볼 수 있었습니다.
그럼 미래를 준비하는 데이터 엔지니어는 무엇일까요? 아직 주니어도 되지못한 입장에서 이런 말을한다는게 다소 우습게 느껴질 수 도 있지만, 어쨌든 제가 생각한 미래의 데이터 엔지니어는 오픈소스를 잘쓰는 것에 그치는 것이 아니라 클라우드 서비스를 활용해서 자기생산성을 극대화할 수 있는 사람이 아닐까하는 생각이 들었습니다.
오픈 소스로도 잘 쓸줄 알고 서비스를 활용해서 시간을 아낄 수도 있고, 이러한 서비스들을 엮어 최종적인 산출물(데이터 파이프라인)을 잘 만들어 낼줄 아는 사람. 그런 사람이 미래의 데이터 엔지니어가 아닐까하고 말이죠.
그래서 가볍게 GCP의 fully managed service를 활용한 데이터 엔지니어링을 해보려합니다. 그동안 오픈소스로 사용해본 도구가 클라우드에서는 어떠한 방식으로 서비스 되는지 그리고 상당히 유명한 Data warehouse인 bigquery는 무엇인지 가볍게 맛보는 시간이 될 것입니다.
아키텍처
GCP 기반의 데이터 엔지니어링을 위한 간단한 아키텍쳐 구상입니다.

Twitter API로 트위터에서 발생하는 실시간 트윗을 수집합니다. 이렇게 수집한 데이터는 실시간으로 PUB/SUB에 전달됩니다. PUB/SUB은 KAFKA와 유사한 개념으로써 실시간 메세징 처리를 위한 GCP의 서비스입니다. 데이터 수집과 PUB/SUB에 전달하는 과정은 파이썬 기반의 코드로 구현하며 GKE를 활용해 클라우드에 App으로 배포까지 진행하여 자동화합니다.
pub/sub에 들어온 데이터들에 대한 고도의 가공작업을 수행하진 않습니다. 다만 해당 데이터를 데이터 웨어하우스인 biquery에 적재하기 위해 파이썬으로 간단한 함수를 작성할 겁니다. 그리고 이를 트리거 하기 위해 cloud functions를 사용합니다. cloud functions는 ‘pub/sub 메세지 큐에서 들어오는 메세지가 있을 때’와 같은 조건을 걸고 이 조건이 충족됐을때 코드를 트리거 시켜주는 역할을 수행합니다.
최종적으로는 bigquery에 적재된 데이터를 가지고 대쉬보드를 간단하게 구현합니다. 이를 위해서 GCP의 시각화 서비스인 Looker Studio를 사용합니다.
Twitter 데이터 수집
우선 Twitter API를 통해 실시간 트윗을 수집해야합니다. 이는 python 코드로 작성할 것이기 때문에 트위터 API에 대한 접근을 가능하게 하는 파이썬 패키지인 tweepy를 사용할 겁니다. 그리고 수집되는 트윗 데이터를 pub/sub으로 전송하기 위해서 google-cloud-pubsub도 사용합니다.
1
2
pip install google-cloud-pubsub
pip install tweepy
트위터 데이터 수집 코드는 tweepy 홈페이지에 나와있는 streamingClient에 대한 내용을 참고하여 작성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
import tweepy
import json
bearer_token = 'Put your bearer_token here'
# tweepy.StreamClient 클래스를 상속받는 클래스
class TwitterStream(tweepy.StreamingClient):
def on_data(self, raw_data):
raw_data = json.loads(raw_data.decode('utf-8'))
raw_data = raw_data['data']
# 영어 트윗만 가져오기
if raw_data['lang'] == 'en':
tweet = json.dumps({'id': raw_data['id'], 'created_at': raw_data['created_at'], 'text': raw_data['text']}, default=str)
print(tweet)
def on_error(self, status_code):
print(status_code)
if status_code == 420:
return False
# 규칙 제거 함수
def delete_all_rules(rules):
# 규칙 값이 없는 경우 None 으로 들어온다.
if rules is None or rules.data is None:
return None
stream_rules = rules.data
ids = list(map(lambda rule: rule.id, stream_rules))
client.delete_rules(ids=ids)
# 스트림 클라이언트 인스턴스 생성
client = TwitterStream(bearer_token)
# 모든 규칙 불러오기 - id값을 지정하지 않으면 모든 규칙을 불러옴
rules = client.get_rules()
# 모든 규칙 제거
delete_all_rules(rules)
# 스트림 규칙 추가
client.add_rules(tweepy.StreamRule(value="netflix"))
# 스트림 시작
client.filter(tweet_fields=["lang", "created_at"])
위 코드를 실행하기 위해서는 twitter developer에서 가입한 후 bearer_token을 발행받아야 합니다. 참고로 휴대폰 인증이 완료된 트위터 아이디로만 가입이 가능합니다.
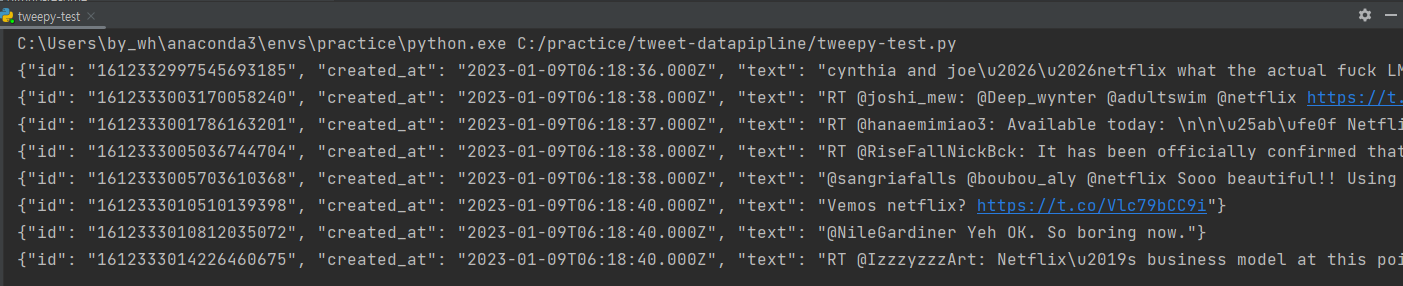
결과적으로 코드를 실행하면 위와 같이 실시간으로 트윗 데이터가 들어오는 것을 확인할 수 있습니다.
pub/sub으로 실시간 데이터 보내기
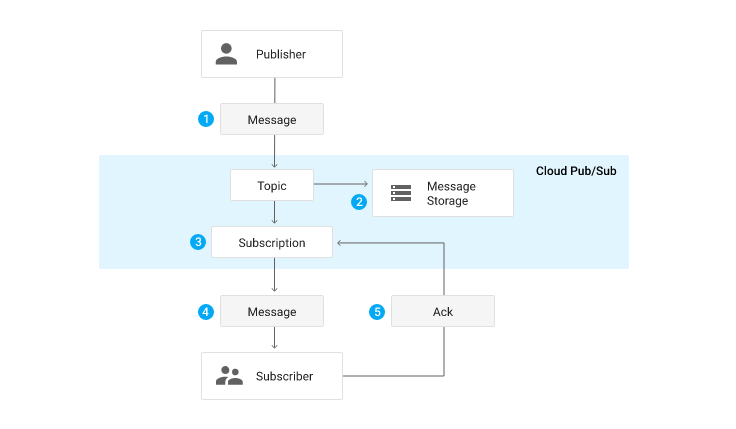
pub/sub은 GCP의 완전 관리형 실시간 메세징 서비스입니다. KAFKA와 상당히 유사하며 실제로 topic - subscription의 개념이 사용됩니다.
앞서 얻은 실시간 트윗 데이터를 google cloud의 pub/sub으로 보내기 위해서는 GCP에서 pub/sub에 관한 몇가지 작업이 선행되어야 합니다.
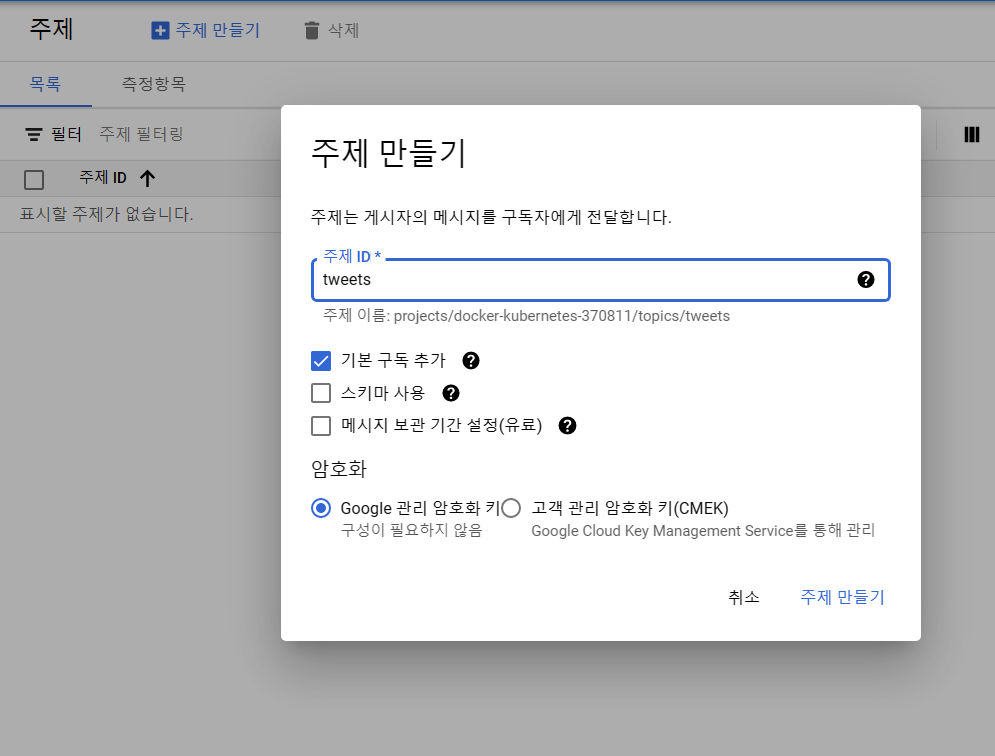
일단 GCP 콘솔에서 탐색이나 검색을 활용해 Pub/Sub으로 접근한 후 주제(topic)를 만들어줍니다. 주제 ID는 이후 코드를 작성할 때 필요하기때문에 구분가능한 것으로 작성하고 기본 구독(subscribe)을 추가해줍니다.
사실 계획상으로는 pub/sub에서 바로 bigquery로 전달하는 게 맞지만, 주제(topic)에 데이터가 들어가는지 확인을 하기위해선 해당 주제에 대한 구독(subscription)이 필요하기 때문에 기본 구독을 사용하는 방향으로 주제를 만들겠습니다.
주제를 만들고 나면 이젠 이전에 작성했던 코드에 pubsub으로 수집되는 트윗 데이터를 전송하는 코드를 추가해줄 차례입니다. 해당 파트는 공식 홈페이지에 나와 있는 pubsub 코드 샘플을 참조하여 작성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
import tweepy
import json
import os
from google.cloud import pubsub_v1
# access credentials 지정
os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = 'docker-kubernetes-370811-f49003f1ee92.json'
bearer_token = 'AAAAAAAAAAAAAAAAAAAAAB9klAEAAAAATKriHYL257FK%2BMhE8oQK8ozffZw%3DUT4XYu8OLE3zxaqdIMC1gi8Oji0Mf8Z3rmWHXxYGpv6lAL2UdP'
# pub/sub publisherClient 생성
publisher = pubsub_v1.PublisherClient()
topic_name = 'projects/{project_id}/topics/{topic}'.format(
project_id='docker-kubernetes-370811',
topic='tweets', # pub/sub 주제(topic) 지정
)
# tweepy.StreamClient 클래스를 상속받는 클래스
class TwitterStream(tweepy.StreamingClient):
def on_data(self, raw_data):
raw_data = json.loads(raw_data.decode('utf-8'))
raw_data = raw_data['data']
#print(raw_data)
# 영어 트윗만 가져오기
if raw_data['lang'] == 'en':
tweet = json.dumps({'id': raw_data['id'], 'created_at': raw_data['created_at'], 'text': raw_data['text']}, default=str)
# topic으로 publish
future = publisher.publish(topic_name, data=tweet.encode('utf-8'))
future.result()
print(tweet)
def on_error(self, status_code):
print(status_code)
if status_code == 420:
return False
# 규칙 제거 함수
def delete_all_rules(rules):
# 규칙 값이 없는 경우 None 으로 들어온다.
if rules is None or rules.data is None:
return None
stream_rules = rules.data
ids = list(map(lambda rule: rule.id, stream_rules))
client.delete_rules(ids=ids)
# 스트림 클라이언트 인스턴스 생성
client = TwitterStream(bearer_token)
# 모든 규칙 불러오기 - id값을 지정하지 않으면 모든 규칙을 불러옴
rules = client.get_rules()
# 모든 규칙 제거
delete_all_rules(rules)
# 스트림 규칙 추가
client.add_rules(tweepy.StreamRule(value="netflix"))
# 스트림 시작(expension 사용)
client.filter(tweet_fields=["lang", "created_at"])
pubsub Client로 publisher를 만들고 앞서 만든 주제를 지정한 다음 tweepy로 수집되는 실시간 트윗 데이터를 pubsub에 게시합니다.
추가로 google-cloud-pubsub과 같은 google-cloud API를 사용하기 위해서는 Acess Credential을 발급받아야합니다. 해당 과정은 GCP 홈페이지에 상세히 나와 있습니다.

발급받은 파일은 작성한 파이썬 파일과 같은 위치에 두어 os.environ으로 간단히 지정할 수 있도록 했습니다.
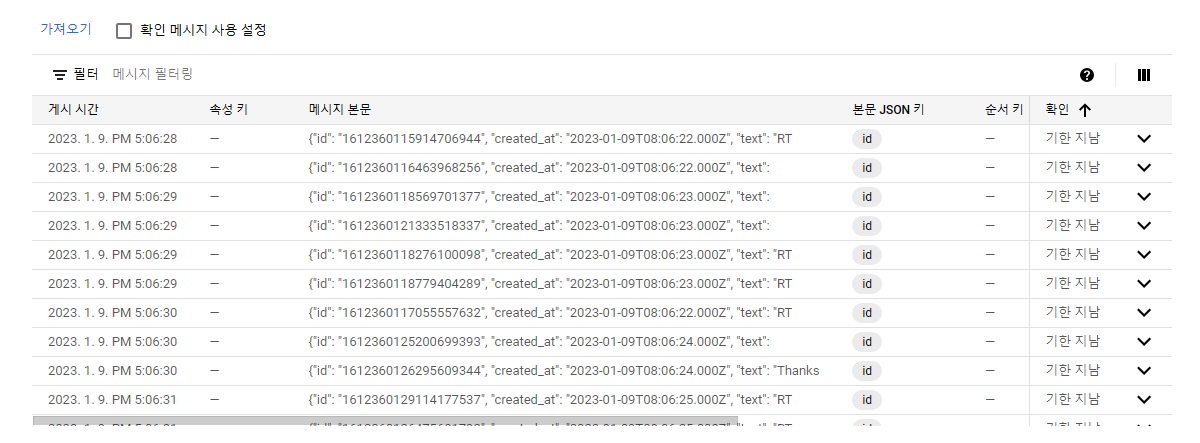
이제 코드를 실행시키고 GCP 콘솔로 돌아가 해당 topic의 구독에서 메세지를 확인하면 아래와 같이 데이터가 실시간으로 쌓이는 것을 확인 할 수 있습니다.
마무리
이번 포스팅에서는 트위터 api를 통해 실시간 트윗 데이터를 수집하는 전체 파이프 라인의 전반부를 완성했습니다. 이어지는 포스팅에서는 실시간을 수집되는 트윗을 Data Warehouse인 BigQuery에 적재하는 작업을 수행할 예정입니다. 이를 위해 cloud funtions을 사용하며 bigquery에 적재된 데이터는 Looker Studio로 간단한 수준의 시각화까지 진행할겁니다.
Reference
StreamingClient — tweepy 4.12.1 documentation
Python client library Google Cloud