지난 포스팅에서는 트위터 실시간 API를 통해 수집되는 데이터를 Pub/Sub으로 보내는 작업을 수행했습니다. 이젠 Cloud funtions를 사용하여 pub/sub으로 데이터가 들어올 때, Data Warehouse인 BigQuery로 전송하는 작업을 진행합니다.
BigQuery 설정
빅쿼리는 GCP의 완전 관리형 SQL 데이터 웨어하우스로 솔루션으로써 매우 큰 데이터도 매우 저렴하게 저장하고 빠른 처리 속도를 가지고 있다는 장점이 있습니다.
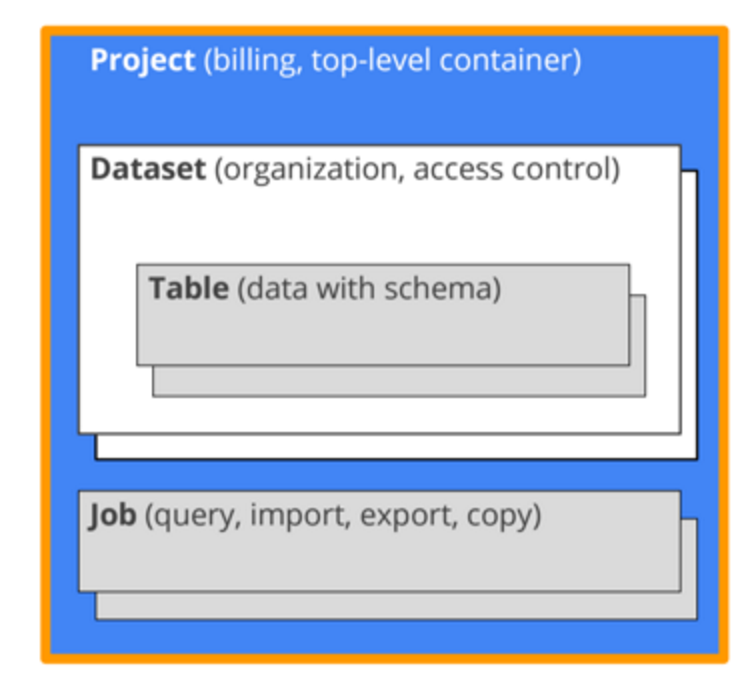
빅쿼리에 데이터를 적재하기 위해서는 저장할 공간을 마련해주어야합니다. 이를 데이터 셋이라고 부릅니다. MySQL로 비유하자면 Database에 해당하며 실제로 빅쿼리의 데이터 셋도 테이블의 집합입니다.
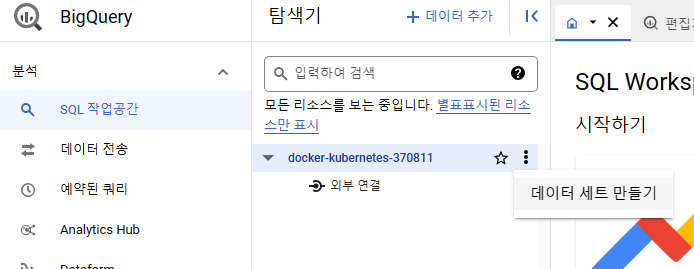
데이서 셋은 콘솔작업으로 쉽게 생성할 수 있습니다.
그리고 테이블도 하나 생성해 줍니다.
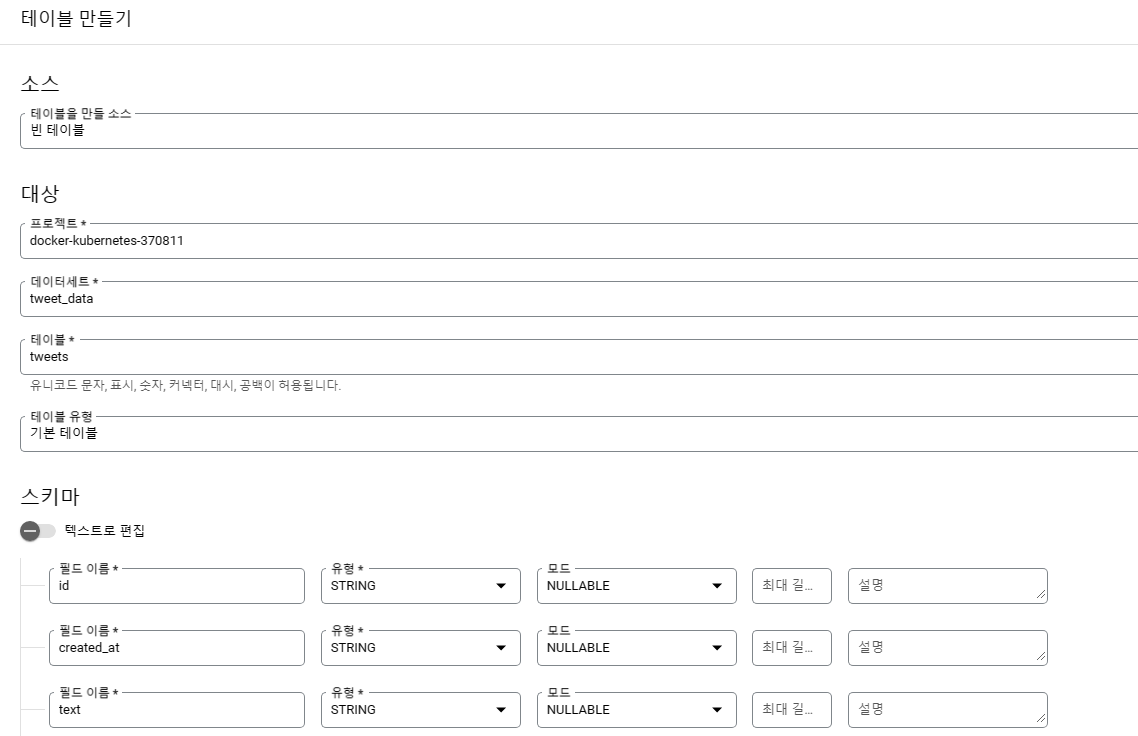
pub/sub으로 인입되는 데이터를 고려해서 작성해야합니다. 저의 경우 코드레벨에서부터 아이디, 작성시간, 트윗 내용만을 수집하고 있기 때문에 테이블도 이에 맞춰 작성했습니다.
다만 이 과정에서 한 가지 주의할 점은 데이터 세트와 테이블 이름은 빅쿼리로 데이터를 전송할 때 코드 상에서 명시적으로 기입해야하므로 구분이 가능하게 작성해 두는것이 좋습니다.
Pub/sub에서 BigQuery로 데이터 전송
Pub/Sub에 들어오는 데이터는 BigQuery로 전송될 겁니다. 이를 위해서 사용하는 것이 Cloud Functions 입니다. Cloud Functions은 구글 클라우드의 서버리스 제품으로써 트리거 조건과 코드를 설정하면, 원하는 동작을 자동으로 수행합니다. 즉, ‘pub/sub에 데이터가 인입되면, bigquery로 데이터를 전송하라’는 동작을 설정할 수 있다는 것입니다.
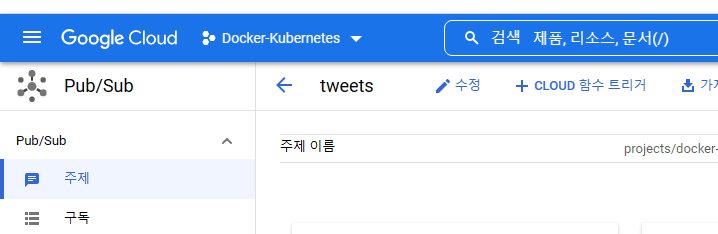
실제로 pub/sub에서 cloud function 설정을 바로 할 수 있습니다. 이렇게 접근하면 자동으로 트리거 유형이 pub/sub에 데이터가 인입될 때로 설정이 됩니다.
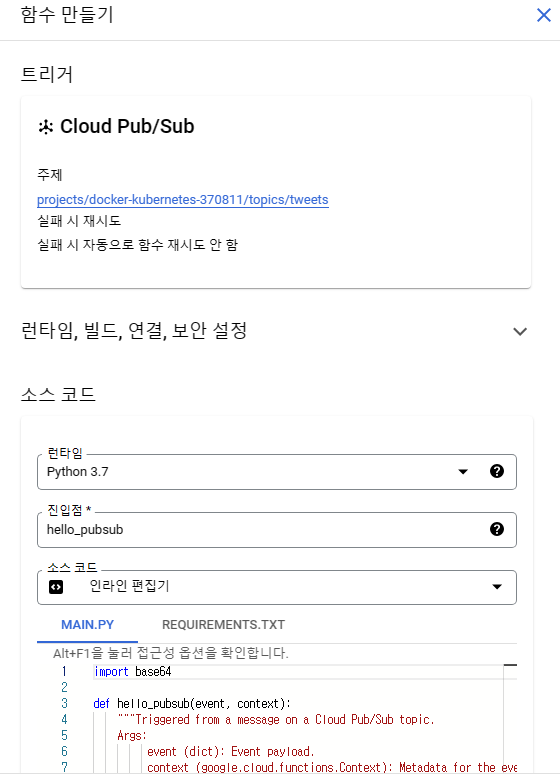
그리고 소스코드를 작성해주면 되는데, 런타입은 프로그래밍 언어를 설정해주는 부분이고, python으로 설정했기 때문에 main.py에 트리거 시킬 코드를 작성하고 requirements에는 필요한 라이브러리를 기입해주면 됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
# main.py
import base64
import json
from google.cloud import bigquery
def tweets_to_bq(tweet):
client = bigquery.Client()
dataset_ref = client.dataset('tweet_data')
table_ref = dataset_ref.table('tweets')
table = client.get_table(table_ref)
tweet_dict = json.loads(tweet)
rows_to_insert = [
(tweet_dict['id'], tweet_dict['created_at'], tweet_dict['text'])
]
error = client.insert_rows(table, rows_to_insert)
print(error)
def hello_pubsub(event, context):
"""Triggered from a message on a Cloud Pub/Sub topic.
Args:
event (dict): Event payload.
context (google.cloud.functions.Context): Metadata for the event.
"""
pubsub_message = base64.b64decode(event['data']).decode('utf-8')
print(pubsub_message)
tweets_to_bq(pubsub_message)
1
2
3
# requirements.txt
google-cloud-bigquery
파이프 라인 동작 확인
이제 구축한 파이프라인이 제대로 작동하는지 확인해볼 차례입니다. 즉, 생성해놓은 빅쿼리 테이블에 데이터가 정상적으로 적재되고 있느지를 확인한다는 것입니다. 이 것이 확인되야 빅쿼리에 적재된 데이터를 활용하여 Looker Studio로 시각화 할 수 있습니다.
우선 로컬에 작성해둔 트위터 데이터 수집기를 작동시켜 봅니다.
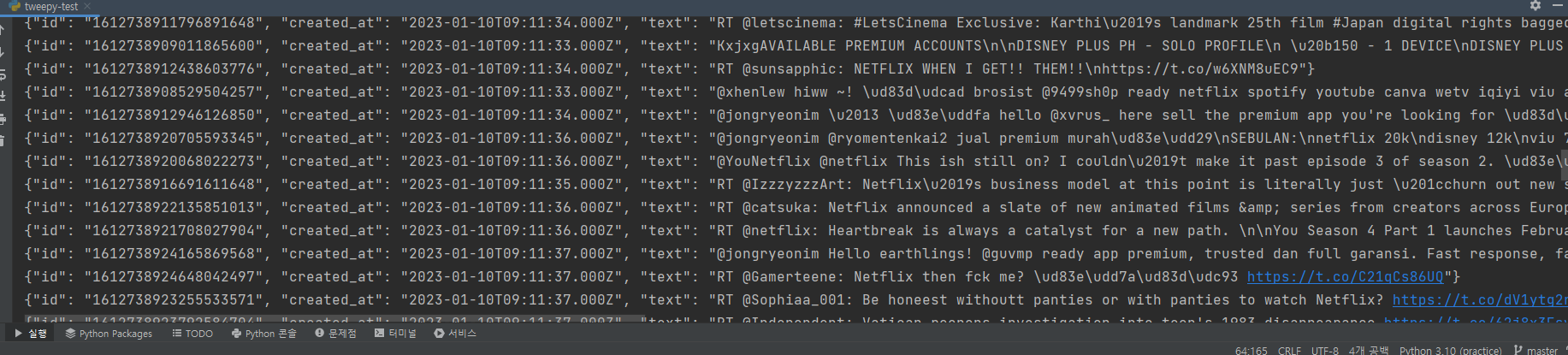
그리고 빅쿼리에서 쿼리문을 날려보면 데이터가 해당 테이블에 정상적으로 쌓이고 있는 것을 확인할 수 있습니다.
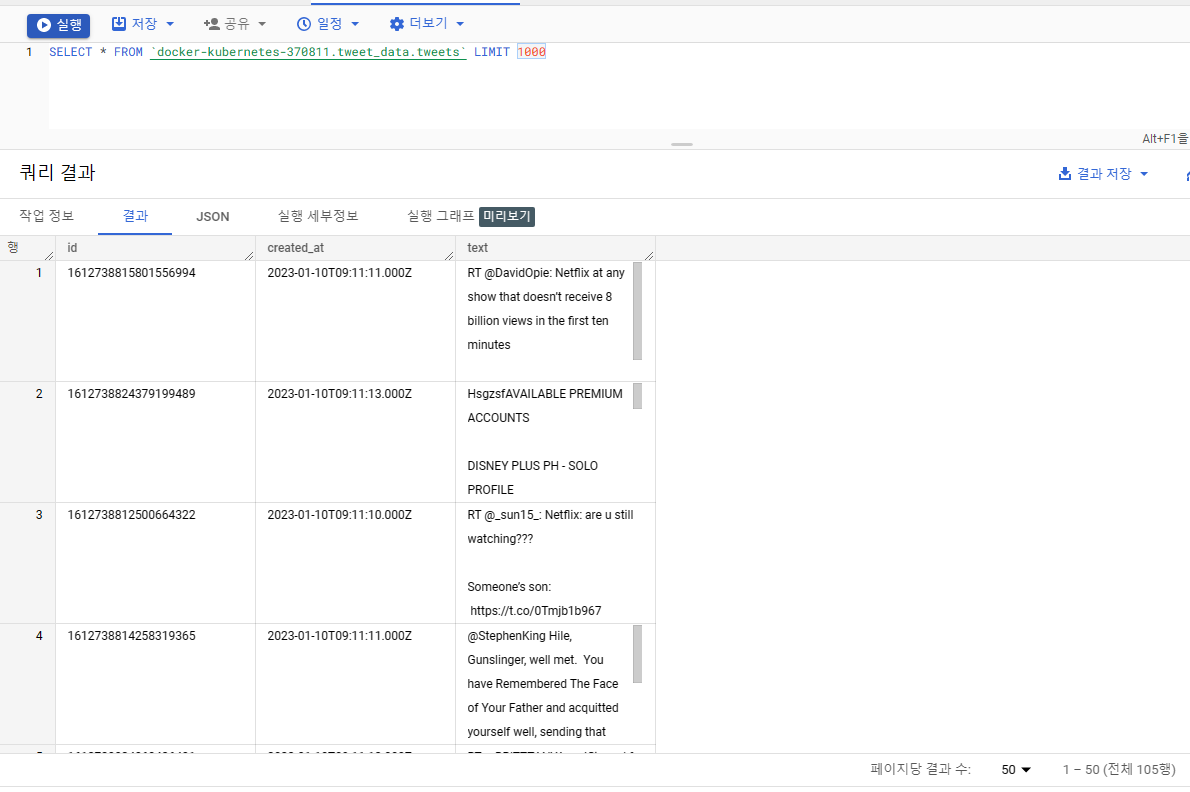
빅쿼리에서 SELECT * FROM docker-kubernetes-370811.tweet_data.tweets LIMIT 1000 이라는 쿼리문을 실행 시켰고, 테이블에 데이터가 쌓이고 있는 것을 했습니다. 이로써 정상적으로 파이프 라인이 작동하는 것을 확인할 수 있었습니다.
Looker Studio(구 Data Studio)를 통한 시각화
이제 빅쿼리에 적재된 데이터를 Looker Studio로 시각화할겁니다. Looker Studio는 이전에는 DataStudio라는 이름이였던 구글 클라우드의 대쉬보드 솔루션입니다.
빈 보고서를 만들면 보고서에 데이터를 추가하라는 창이 하나 나타납니다. 구글 시트, 구글 애널리틱스, 구글 서베이, 구글 애드 등 구글의 다양한 서비스뿐만 아니라 다양한 DB(AWS Redshift, MySQL, PostgreSQL 등)과도 연결할 수 있습니다.
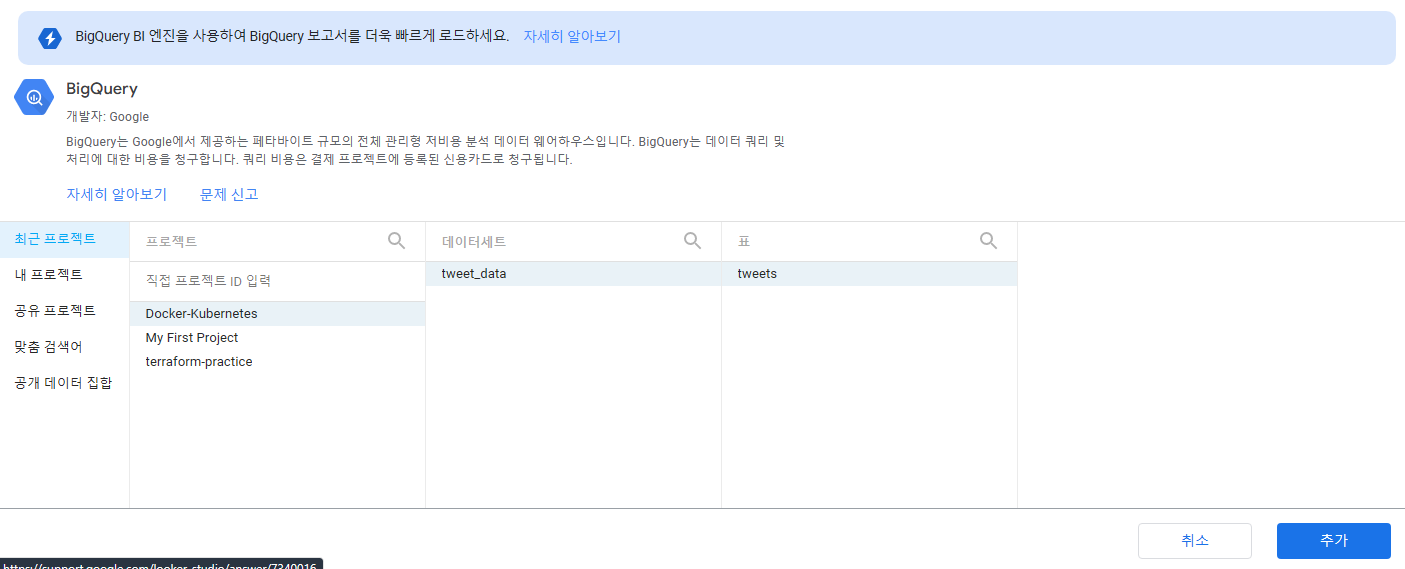
저는 BigQuery에 적재된 데이터를 활용하여 시각화할 계획이기 때문에 BigQuery를 선택해서 보고서를 만들어 주겠습니다. 사용하는 프로젝트, 데이터세트, 테이블만 지정해주면 바로 보고서 생성이 가능합니다.
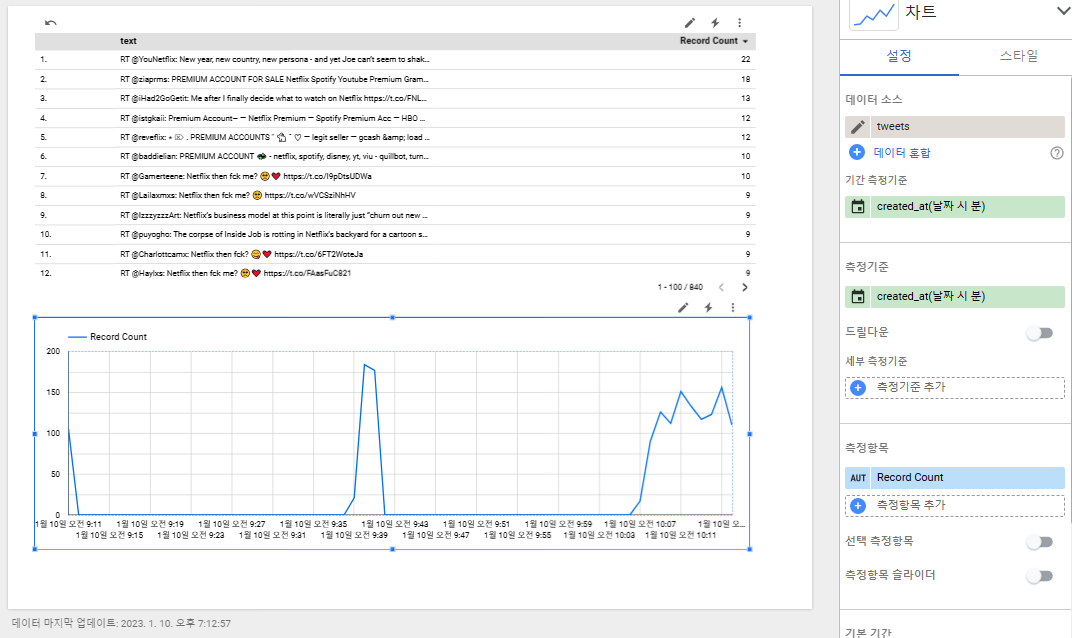
중간중간 코드를 중단시켜서 데이터 흐름이 끊기긴 했지만 어쨌든 수백개의 트윗 데이터가 빅쿼리에 쌓였고 시계열 차트를 그릴 수 있을 정도의 데이터 흐름을 확인할 수 있었습니다.
사실 Looker Studio가 그렇게 좋은 대시보드 툴은 아닙니다. 무료라는 장점과 구글 클라우드와의 연동성이 상당히 용이하다는 장점은 있지만 기능성 측면에서 다른 대시보드 툴인 Tableau, Holistics, Redash, Metabase, Superset 등에 비해 부족한 것이 사실입니다. 더 전문적인 수준의 대쉬보드를 만드는 경험을 쌓고 싶다면 앞에 열거한 도구들을 사용하는 편이 더 좋습니다.
마무리
구글 클라우드 기반의 데이터 파이프라인이 거의 완성되었습니다. 이제 해야할 작업은 GKE로 로컬에 작성한 트위터 API기반 실시간 데이터 수집기를 구글 클라우드에 배포하여 데이터 파이프라인의 완전한 자동화를 달성하는 것입니다.
이를 위해 Dockerfile을 생성할 것이고 이를 사용해 GKE를 통한 APP 배포를 목표로합니다. 자세한 내용은 다음 포스팅에서 다루도록 하겠습니다.