GCP 기반 데이터 엔지니어링을 위한 마지막 단계인 GKE의 사용이 남았습니다. 지난 포스팅에서도 언급했지만 GKE는 쿠버네티스 기반의 구글 클라우드 서비스이며 어플리케이션을 배포하기 위한 용도로 사용됩니다.
도커 이미지 만들기
쿠버네티스 pod을 생성하기 위해선 컨테이너 이미지가 필요합니다. 이를 위해서 dockerfile을 만들어서 컨테이너 이미지를 빌드할겁니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# dockerfile
# temp stage
FROM python:3.7-slim as builder
WORKDIR /app
ADD . /app
ENV PYTHONDONTWRITEBYTECODE 1
ENV PYTHONUNBUFFERED 1
ENV GOOGLE_APPLICATION_CREDENTIALS="/app/docker-kubernetes-370811-f49003f1ee92.json"
ENV DEBIAN_FRONTEND noninteractive
ENV DEBCONF_NOWARNINGS="yes"
RUN apt-get update && \
apt-get install -y --no-install-recommends gcc \
apt-utils
RUN python -m venv /opt/venv
ENV PATH="/opt/venv/bin:$PATH"
COPY requirements.txt .
RUN python -m pip install --upgrade pip
RUN python -m pip install -r requirements.txt
# final stage
FROM python:3.7-slim
**COPY --from=builder /opt/venv /opt/venv
WORKDIR /app
ADD . /app
ENV PATH="/opt/venv/bin:$PATH"
CMD ["python", "tweepy-test.py"]
그리고 requirements.txt 파일도 만들어 줍니다.
1
2
3
4
# requirements.txt
google-cloud-pubsub==2.13.11
tweepy==4.12.1
구글 credentials 파일과 작성해둔 tweepy 코드파일도 dockerfile, requirement.txt와 같은 디렉토리에 위치시킵니다.

마지막으로 docker build -t tweet . 이라는 도커 커맨드를 통해 현재 디렉토리를 대상으로 도커 이미지 빌드를 합니다. 참고로 -t 옵션을 통해 tweet이라는 이름으로 이미지를 만들었습니다.
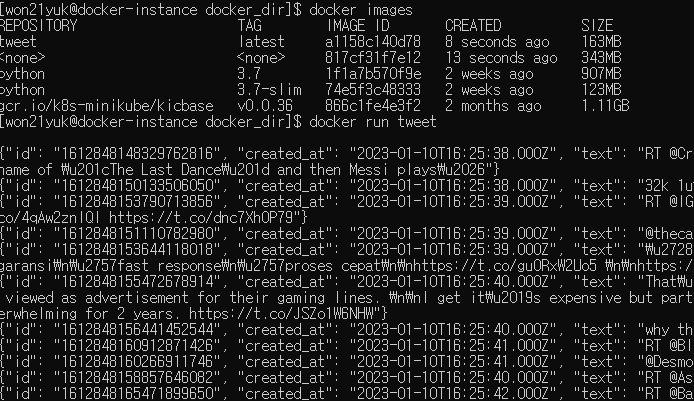
docker images 커맨드로 이미지를 확인하면 tweet이라는 이름의 도커 컨테이너 이미지가 생성된 것을 확인할 수 있습니다. 그리고 해당 컨테이너를 실행시키면 트윗 데이터가 수집되는 것도 확인할 수 있습니다.
Container Registry에 도커 이미지 등록
GCP는 컨테이너 이미지를 등록할 수 있는 Container Registry라는 서비스를 제공합니다. 이곳에 이미지를 업로드하기 위해서는 Docker와 Container Registry가 상호작용하기 위한 엑세스 권한을 부여해야합니다.
인증방식에는 gcloud가 공식적으로 권장되지만, 저의 경우 이전 과정에서 pub/sub과 연결을 위해 서비스 계정 키(json 파일)를 받아놨기 때문에 이를 활용할 겁니다. 만약 다른 방식을 사용하고 싶다면 공식홈페이지를 참고하면 됩니다.
1
2
3
4
5
6
7
# 샘플
cat KEY-FILE | docker login -u KEY-TYPE --password-stdin \
https://HOSTNAME
# 예시
cat docker-kubernetes-370811-f49003f1ee92.json | docker login -u _json_key --password-stdin \
https://gcr.io
서비스 계정 키를 사용하여 docker로 인증하는 방법은 아주 간단합니다. 위와 같은 커맨드를 실행시키기만 하면되는데, KEY-FILE에는 자신이 가지고 있는 서비스 계정 키의 이름(*.json)을 포함한 경로를 기입하고 KEY-TYPE은 _json_key 마지막으로 HOSTNAME에는 gcr.io, us.gcr.io, eu.gcr.io, asia.gcr.io 중에 하나를 사용하면 됩니다.

Login Succeeded가 뜨면 인증이 완료된 겁니다. 이젠 앞서 만든 docker 컨테이너 이미지를 Container Registry에 push해주면 됩니다. 다만 해당 이미지의 이름(tweet)를 활용하여 Repository가 Container Registry의 경로가 되도록 설정해준 후에 이미지를 push해줘야 합니다. 이를 위해 아래와 같은 커맨드를 입력해줍니다.
1
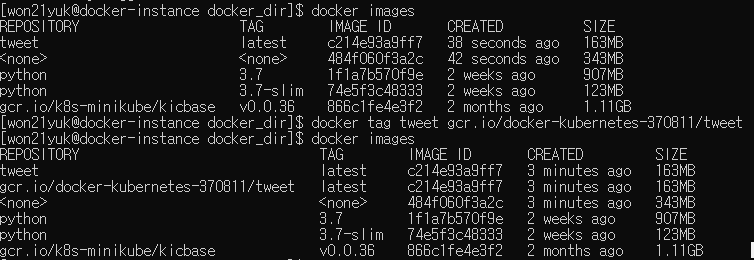
docker tag tweet gcr.io/docker-kubernetes-370811/tweet
커맨드를 실행한 후 도커 이미지를 확인해보면 repository가 gcr.io/docker-kubernetes-370811/tweet으로된 이미지가 추가된 것을 확인할 수있습니다. 이처럼 특정 저장소로 이미지에 태그를 지정하면 해당 repository로 이미지를 push할 수 있습니다.
docker push gcr.io/docker-kubernetes-370811/tweet 커맨드를 입력해 push해줍니다. 이제 Container Registry에서 해당 이미지가 Container Registry의 특정 디렉토리에 저장 된 것을 확인할 수 있습니다.
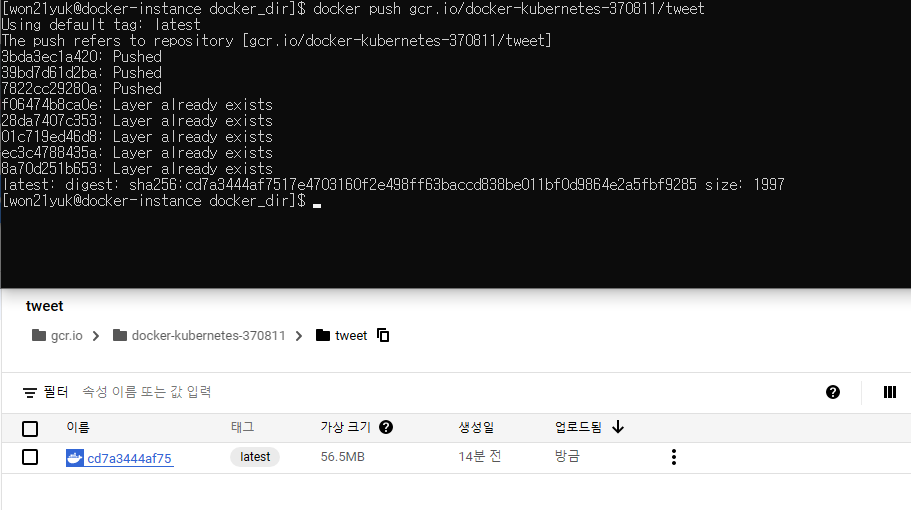
GKE에 도커 이미지 배포
GKE에 배포하는건 앞선 과정에 비하면 상당히 쉽습니다. 사용할 이미지를 선택해 GKE에 배포를 누르기만 하면 사실상 끝납니다.
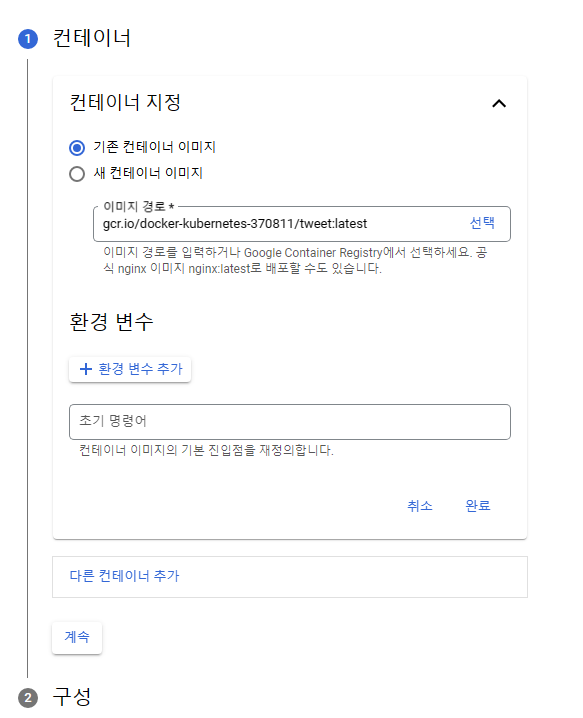
엄밀히 하자면 쿠버네티스의 구성(Deployment, Replicaset, label, Service 등)을 신경써서 작성해야하지만, 그걸 사용할 정도로 깊게 다룰 계획이 없으니 계속버튼을 눌러서 기본옵션대로 빠르게 배포하겠습니다.

컨테이너 로그를 확인하면 실시간으로 트위터 데이터가 수집되는 것을 확인할 수 있습니다. 이정도로 충분하지만 추가로 파이프라인이 제대로 작동하여 bigquery에 잘 쌓이는지도 확인해 보겠습니다.
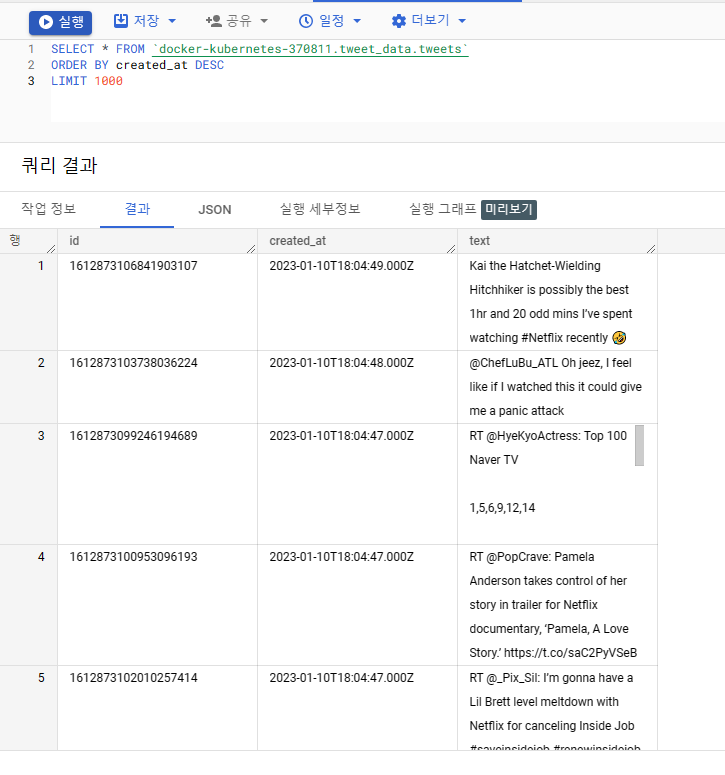
날짜 순으로 내림차순 정렬하도록 쿼리를 날리면 최신 트윗 데이터가 빅쿼리에 쌓이고 있다는 것을 확인할 수 있습니다.
마무리
GCP의 Fully managed service를 활용한 실시간 데이터 파이프라인 구축작업이 이로써 모두 끝났습니다. 이전에 오픈소스로 사용해본 docker, kubernetes, kafka, database(MySQL 등)에 대한 경험을 구글 클라우드가 가진 서비스들에 녹여보는 좋은 경험이였습니다.
모든 과정을 오픈소스로 구축하는 것보다 획기적으로 빠른 속도로 데이터 파이프라인을 구축할 수 있다는 점은 참으로 매력적이였습니다. 다만, 오픈소스로의 사용경험을 통해 다양한 요소들에 대한 지식들이 갖춰지지 않으면 지나치게 서비스 의존적인 데이터 엔지니어가 될 지도 모른다는 우려도 생겼습니다.
따라서 자기생산성이 높은 데이터 엔지니어가 되기위해 퍼블릭 클라우드의 Fully managed service에 대한 경험도 중요하지만, 이를 적당한 상황에서 사용하기 위해 그리고 더 복잡한 매커니즘을 구현하기 위해 오픈소스로 튼튼한 기초를 쌓는 경험의 필요성도 느꼈다는 말로 갈무리하며 포스팅을 마치겠습니다.
Reference
python - WARNING: Running pip as the ‘root’ user - Stack Overflow
| [인증 방식 | Container Registry 문서 | Google Cloud](https://cloud.google.com/container-registry/docs/advanced-authentication) |