이번 포스팅에서는 HDFS에 대한 내용을 본격적으로 다룹니다. 당연한 소리지만 HDFS가 GFS에서 시작된 만큼 초기 HDFS는 GFS의 원리, 특성 그리고 아키텍쳐까지도 상당부분 유사합니다. 용어가 조금씩 달라지는 부분이 있다는 정도로 이해하시면 편할 겁니다.
물론 이후의 하둡이 버전업되면서 HDFS도 독자적인 노선을 밟게 됩니다. 특히 하둡 2.0 버전부터 Namenode의 이중화, JournalNode 도입 등 같은 큰 변화들이 있었습니다. 이러한 점에서 HDFS에 대한 포스팅은 크게 두 파트로 나누어 작성할 예정입니다. 첫째는, HDFS의 초기 모델에 대한 이야기 그리고 둘째는 하둡 2.0버전 이후의 HDFS에 대한 이야기입니다.
(이 포스팅에서의 HDFS는 모두 초기의 HDFS를 의미합니다. 2.0이후의 버전을 다룰때는 별도의 포스팅을 통할 예정입니다.)
1. GFS와 HDFS
GFS에 대해 공부한만큼, GFS와 HDFS를 간단히 비교하는 것으로 첫 단락을 시작해보겠습니다.
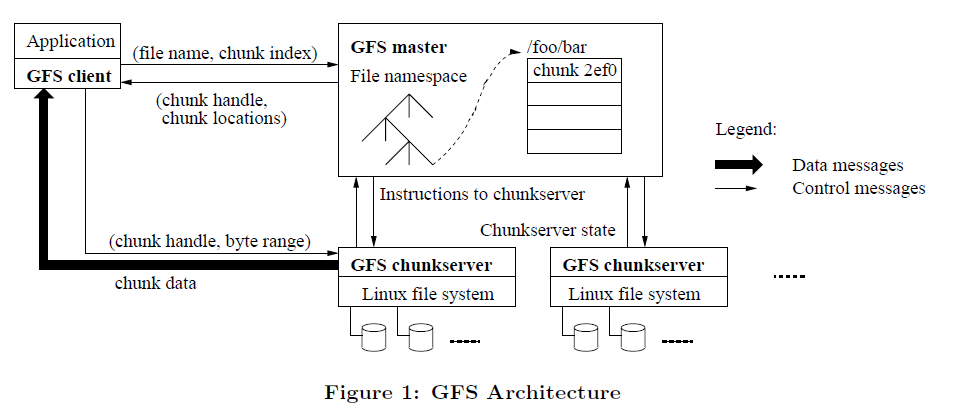
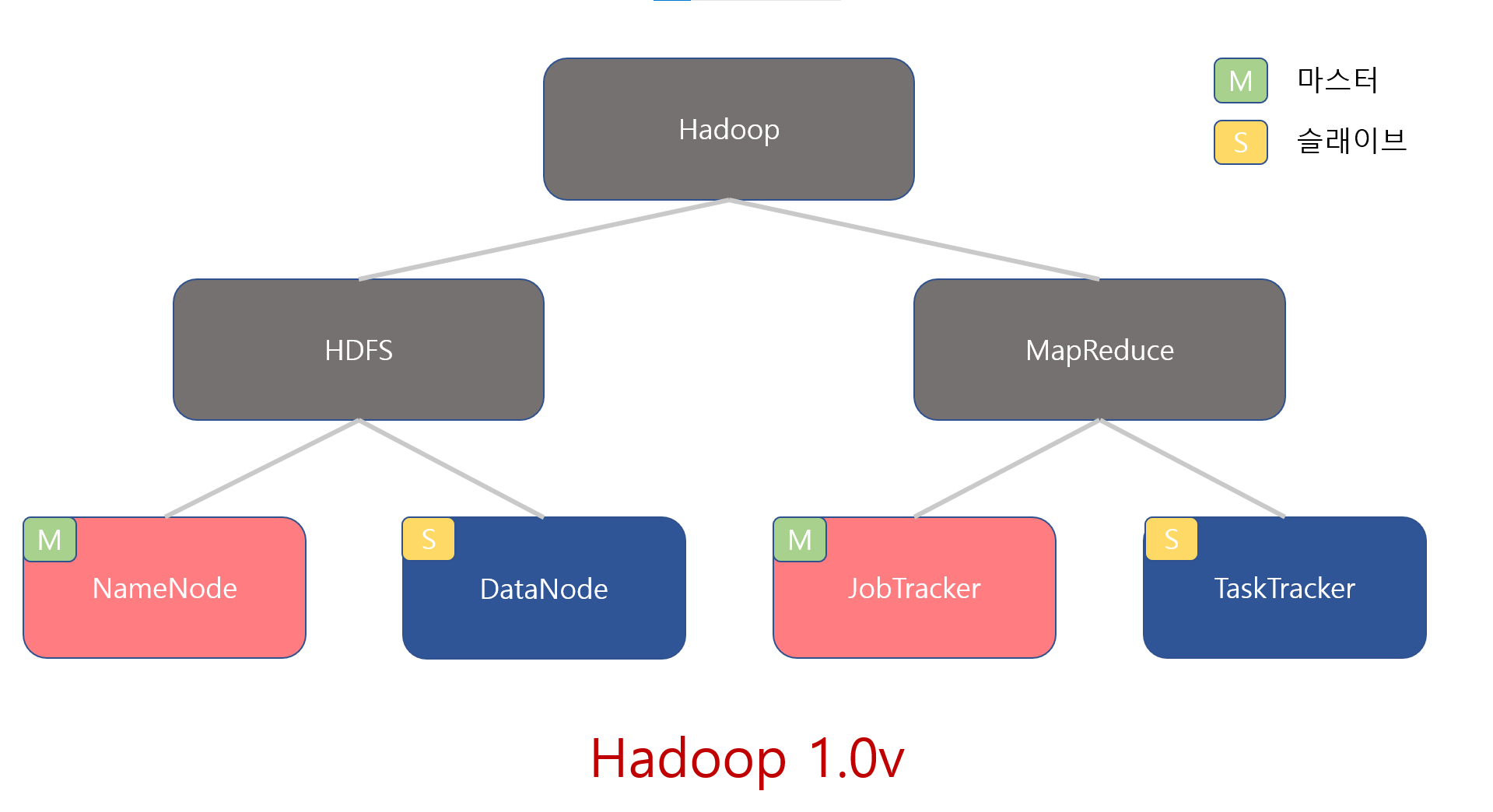
대부분의 분산 시스템은 크게 두 가지 유형으로 나눌 수 있습니다. Master-Slave 구조와 Master가 없는 구조로 말이죠. 보시다시피 GFS는 대표적인 Master-Slave 구조의 분산 시스템입니다. GFS master가 이름 그대로 master이고 GFS chunkserver가 slave입니다.
일반적으로 Master-Slave구조의 시스템에서 slave는 다수로 구성이 되고 쉽게 확장가능합니다. 이를 ‘scale out이 용이하다’라고 말합니다. 이는 비단 하둡에 국한된 것이 아니라 대부분의 분산 플랫폼들이 slave의 scale out이 용이한 아키텍쳐를 가지고 있습니다.
GFS는 Master-Slave구조 중에서도 단일 master와 다수의 slave 구조를 가지고 있습니다. 이러한 구조에서 중요한 건 master에 부하가 가지 않는 환경을 만들어 주는 것입니다. 이는 마스터의 장애가 전체 클러스터의 장애로 이어지기 때문입니다. 이때 마스터를 단일 장애 지점(SPOF, Single Point Of Faillure)라고 부릅니다. (자세한 이야기는 하둡 2.0버전에 대해 다룰때 하겠습니다.)
위의 그림에서 굵은 화살표로 표현된 chunk data 부분을 보면, 실제 청크 데이터를 주고받는 작업은 클라이언트와 chunkserver 사이에서만 일어난다는 것을 확인할 수 있습니다. 데이터를 주고받는 일은 트래픽이 많이 발생하기 때문에 이를 chunkserver에 전담시켜 최대한 마스터에 부하가 가지않도록 설계한 것이죠.
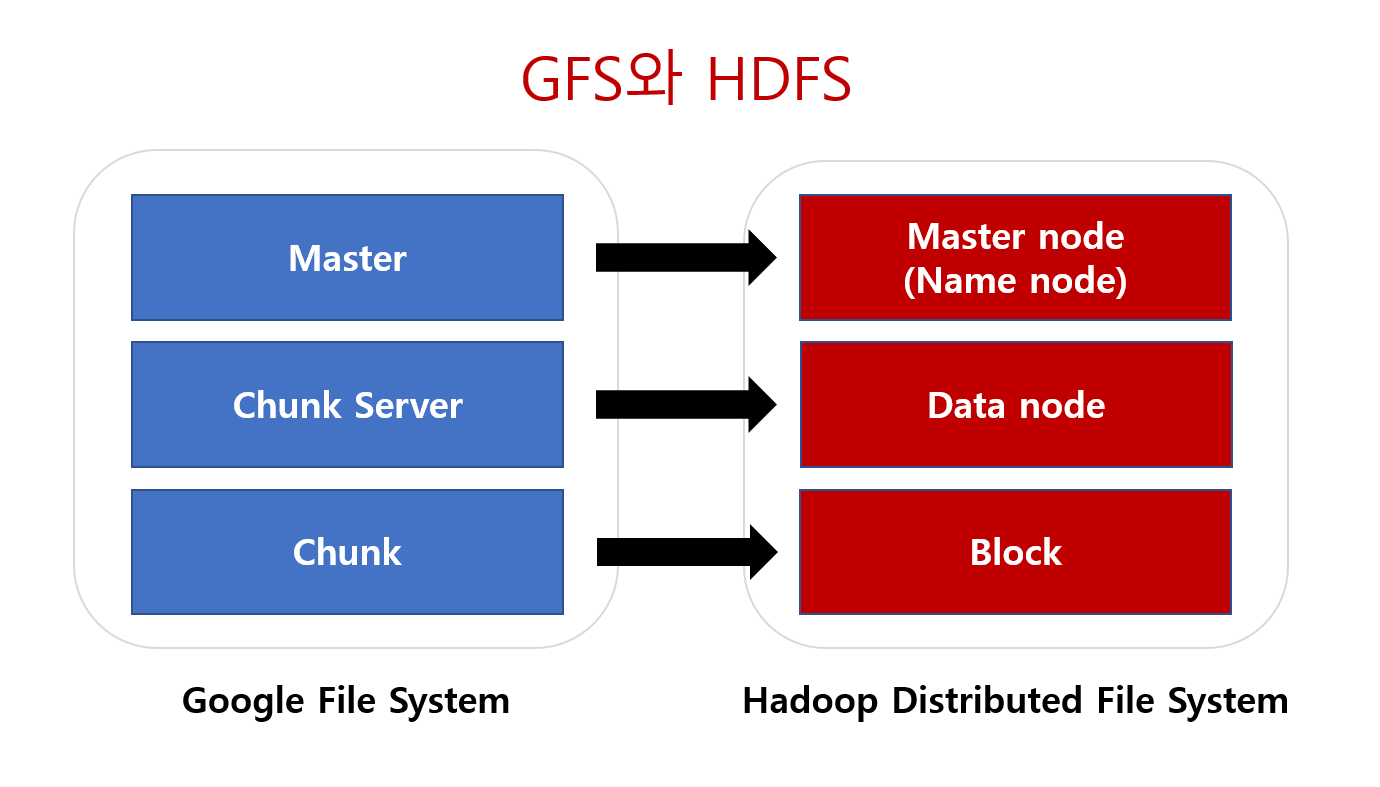
이번엔 HDFS를 보도록 하죠. HDFS도 Master-slave 구조를 가지고 있습니다. 앞서 말했듯 GFS와 상당히 유사한 형태죠. 다만, 일부 다른점도 존재합니다. 가령 GFS Master는 HDFS에서는 Name Node로 불리고 GFS의 Chunk Server는 Data Node라고 불립니다. 이뿐만아니라 GFS에서는 본적없던 Secondary namenode, fsimage, edits가 등장합니다. 물론 개념자체는 GFS에서 차용된 개념들이긴 합니다.
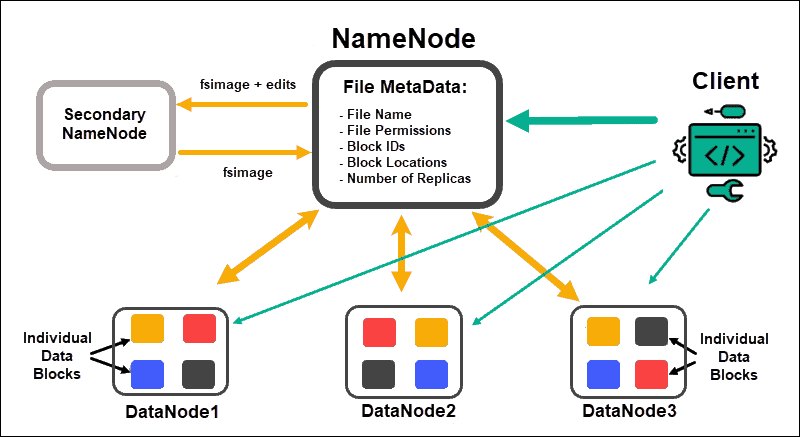
또한 HDFS도 GFS와 마찬가지로 단일 master와 다수의 slave구조를 가지고 있습니다. 이때문에 HDFS 역시 scale out이 용이하죠. 그리고 HDFS도 master의 부하를 줄이기위해 실제 데이터를 주고받는 작업은 Client와 Datanode 사이에서만 발생하록 설계되었습니다.
2. HDFS란?
HDFS는 하둡 클러스터 내에서 스토리지 계층을 담당하는 소프트웨어로서 하둡의 모듈 중 하나로 패키지에 포함되어 있습니다. 쉽게 말하자면, HDFS는 하둡의 기본 스토리지 시스템인 것입니다.
실제로 HDFS는 세계에서 가장 신뢰할 수 있는 스토리지 시스템 중 하나로 인정받습니다. HDFS는 하둡 클러스터에 저장되는 매우 큰 파일들을 분산 저장하여, 일부 서버에 장애가 생긴 경우에도 다른 서버를 통해 데이터에 접근할 수 있는 신뢰성 있는 시스템을 형성해주기 때문이죠.
결국 HDFS의 핵심은 파일을 분산해서 자장하는 시스템이라는 것 입니다. 그리고 이 시스템은 하둡 클러스터에서 작동하죠. 그래서 HDFS의 구성, 특징, 작동방식 등을 이해하기 위해선 이 하둡 클러스터에 대해 미리 알아둘 필요가 있습니다.
1) 하둡 클러스터 네트워크 및 데몬 구성
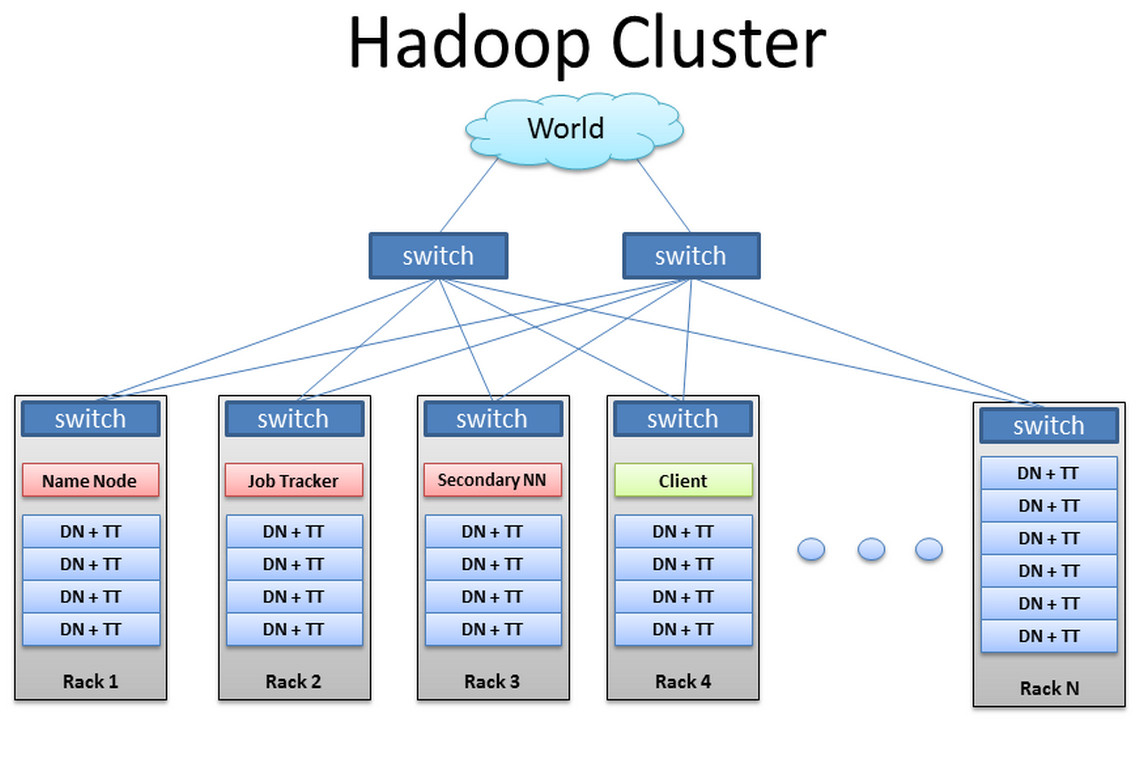
위의 그림은 IDC(Internet Data Center)에 구축된 하둡 클러스터를 간단히 도식화한 것입니다. 이 IDC에서는 Rack형 클러스터로 하둡 클러스터를 구축했고 각 Rack에는 rack 스위치와 여러대의 서버들이 들어가 있습니다. 실제로도 기업들은 하둡 클러스터를 Rack으로 구축하고 수백대의 서버를 하나의 클러스터를 위해 사용합니다.
GFS에서의 가정을 기억한다면, 하둡 클러스터도 상용 하드웨어(commodity hardware)로 구성된 클러스터입니다. rack안에 들어있는 머신들은 각각 하나의 상용 하드웨어이고 서버인것 입니다. 그리고 하둡 클러스터는 master 역할을 하는 서버와 slave 역할을 하는 서버로 나누어 집니다.
하둡 클러스터의 master 서버에는 하둡의 모듈들에서 master역할을 하는 데몬(daemon)을 띄웁니다. 같은 맥락에서 slave 서버에서는 slave 역할을 하는 데몬을 띄우겠죠.
위의 하둡 클러스터 그림에서 빨강 박스는 하둡 클러스터에서 master 역할을 하는 서버들을 의미합니다. 일반적으로 마스터 서버에서는 마스터 역할을 하는 데몬 단 하나만 띄웁니다. namenode, job tracker, secondary namenode가 이에 해당하죠. 이는 오롯히 마스터 서버는 마스터 데몬만 실행시켜 안정성을 높히려는 이유에서 입니다. GFS에서 마스터는 항상 부하가 최소화되는 환경으로 구축하였던 것이 HDFS에도 동일하게 적용된 것이죠.
반면 파랑 박스은 하둡 클러스터의 slave역할을 하는 서버들입니다. 그런데 마스터 서버와 달리 복수의 데몬을 실행시켜놓습니다. 위의 그림에서는 모든 슬레이브 서버에 공통적으로 datanode와 task tracker가 데몬으로 실행되어 있습니다.
슬레이브 서버는 다수로 이루어져있기 때문에 마스터 서버처럼 장애를 걱정하기 보단, scale out을 통한 이점을 누리는 것이 더 좋습니다. 그렇기 때문에 slave 역할을 하는 서버에서는 slave 역할을 하는 데몬들을 모두 실행시키는 것입니다. 물론 기본적으로 어떠한 데몬을 띄울지는 전적으로 사용자의 선택에 달려있긴 합니다.
여기서 하둡이 필요한 이유가 나옵니다. 만약 분산 저장 처리 환경을 구축하기 위해서 하둡이 없다면 어떨까요?
다수의 슬레이브 서버를 구성하기 위해 물리적으로 떨어져있는 모든 하드웨어들을 일일히 연결해주고 설정해야한다고 생각해보죠. 클러스터가 2~3개의 서버만 사용한다면 시간은 좀 걸릴지언정 해볼만 할지도 모릅니다. 그러나 서버가 100개 300개 1000개까지 늘어난다고 생각하면, 이는 꽤나 끔찍한 일이 되겠죠.
이를 쉽게 해주는게 하둡입니다. 하둡은 수많은 서버로 클러스터를 구성하는 일과 서버들을 연결하고 클러스터를 확장하는 일 그리고 서버의 역할을 부여하는 일을 하여 대용량 데이터의 분산 저장 및 처리 환경을 갖춰줍니다.
이때, 하둡 자체가 분산 저장하고 분산 처리하는 것이 아니라는 걸 명심하셔야합니다. 하둡은 앞서 말한 환경이 갖춰질수 있는 프레임워크를 제공하는 것 뿐이고 실제로는 하둡의 모듈들의 작동을 통해 분산 저장 및 처리가 이루어집니다. 즉, 분산 저장은 HDFS가하고 분산 처리는 MapReduce가 하기때문에 하둡을 정의할 때 소프트웨어 프레임워크라고 하게되는 것이죠.
말이 좀 길었던거 같으니 짧고 간단하게 정리보죠.
- 하둡 클러스터는 Rack 단위로 클러스터를 구축하는 것이 일반적이다.
- 분산 저장은 HDFS, 분산 처리는 MapReduce가 한다.
- 주요 데몬으로는 HDFS의 NameNode와 MapReduce의 JobTracker가 있다.
- 각각은 DataNode와 TaskTracker라는 슬레이브 데몬을 관리하는 마스터 데몬이다.
- 마스터 데몬은 마스터 서버에서, 슬레이브 데몬은 슬레이브 서버에서 실행된다.
2) 블록(Block)
(1) 블록(Block)이란?
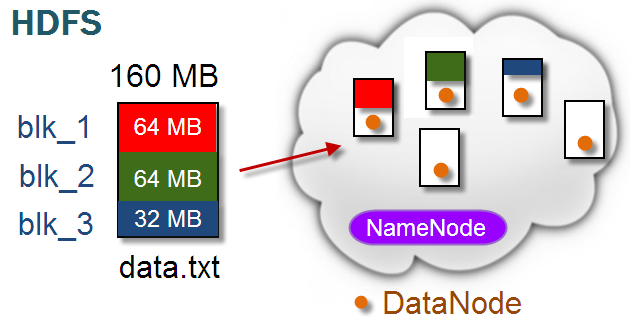
블록(Block)은 HDFS에서 파일이 나눠지는 단위입니다. 좀 더 정확하게는 파일 시스템에 저장되는 가장 작은 단위의 데이터입니다. GFS의 청크(Chunk)와 같은 개념이죠. 따라서 블록사이즈의 디폴트 값도 청크사이즈와 같은 64MB입니다. (이후 하둡 2.0버전으로 업그레이드 되면서 128MB로 증가합니다.)
위의 그림을 보면 160MB짜리 파일이 64MB짜리 블록 2개와 32MB짜리 블록 1개로 나눠지는 것을 볼 수 있습니다. 여기서 우리가 알아야할 건 두가지입니다.
우선 첫째, 블록 사이즈의 설정값이 64MB라는 건 64MB이상의 파일데이터는 64MB의 블록들로 나눠진다는 것을 의미한다.
둘째, 64MB의 블록으로 나누고 남은 데이터는 남은 데이터 크기 만큼의 사이즈를 가진 블록으로 만들어진다.
여기서 뭔가 의아함이 느껴집니다.
분명 앞선 정의에서는 블록이 파일 시스템에 저장되는 ‘가장 작은 단위의 데이터’라고 했습니다. 근데 실제 만들어진 블록 중에 64MB보다 작은 블록이 있습니다. 뭔가 블록의 정의에 모순되는 블록이 만들어진듯하죠.
이러한 현상의 비밀엔 블록이 ‘단위’라는 것에 있습니다. 블록이란건 64MB의 데이터 조각이라는 일차원적인 개념이 아니라, 파일 데이터가 나눠지는 단위 그 자체를 블록이라고 이해해야한다는 겁니다.
다시 풀어 말해보죠. 우리가 블록사이즈를 설정하는 건 블록사이즈의 상한선을 설정하는 개념입니다.
HDFS는 파일이 들어오면 블록이라는 단위로 나눈 후 분산해서 저장할 건데, 그 블록의 크기는 최대 64MB가 되게 하겠다는 거죠. 따라서 64MB씩 꽉꽉 눌러담아서 나눌건데, 만약 남은 파일 데이터의 크기가 64MB보다 작으면 거기에 맞는 블록을 가져와서 담겠다는 겁니다.
단순하게 예를 들어서 1KG짜리 쌀포대를 샀다고 해보죠. 그걸 이제 150g의 쌀을 담을 수 있는 플라스틱 병에 소분할 겁니다. 그러면 150g짜리 플라스틱병을 꽉채워서 6개 나오고, 남은 100g의 쌀은 100g을 담을 수 있는 플라스틱 병에 담습니다. 일부러 150g보다 적게 담거나 100g짜리 플라스틱병이 있는데 150g짜리 플라스틱병을 쓰거나 하진 않을겁니다. 왜냐면 그건 명백히 낭비니까요.
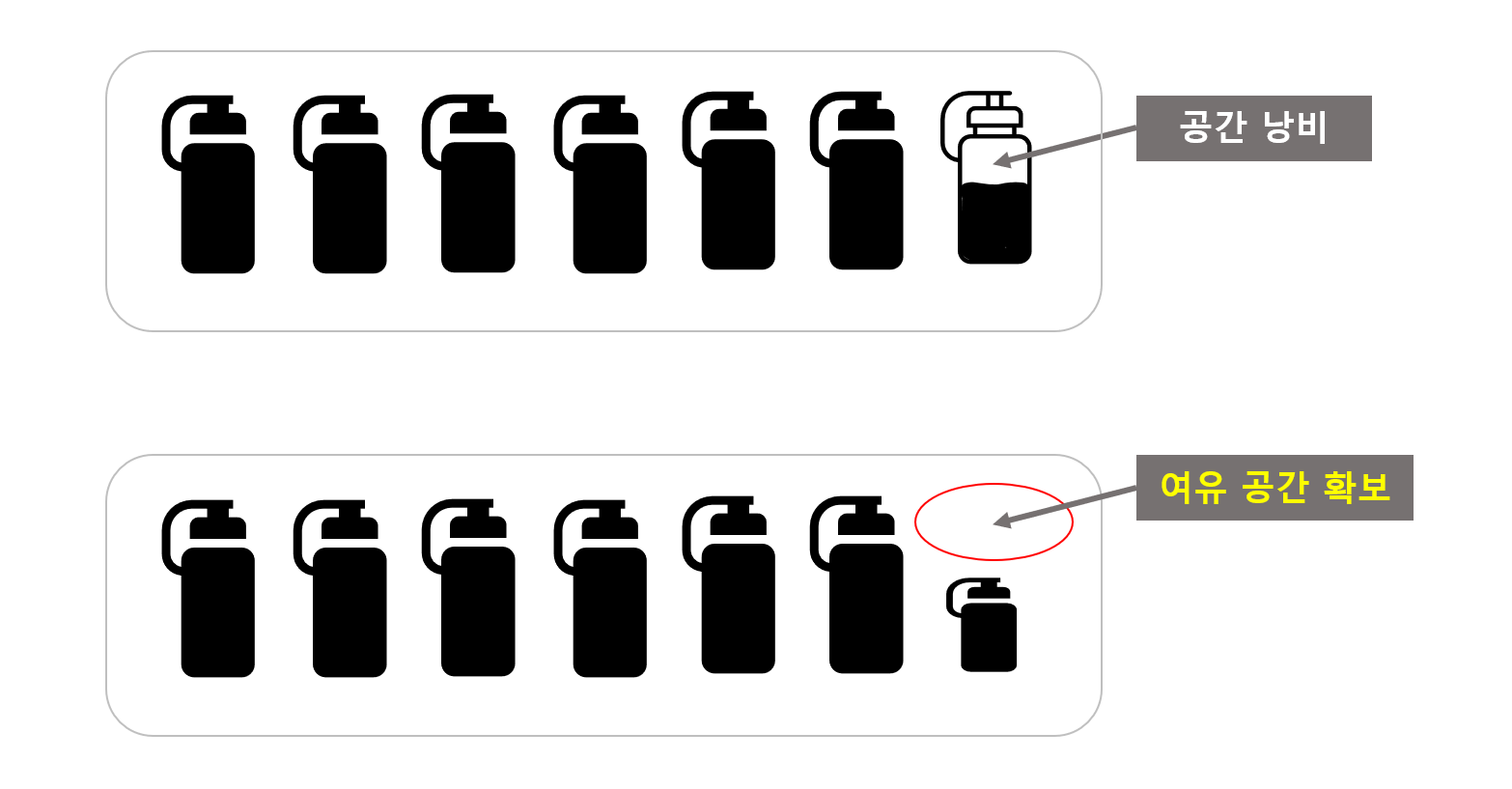
이건 HDFS에서도 같은 맥락입니다. 64MB 블록을 일단 만들고 거기에 32MB만 담는다 하더라도 일단 그 블록사이즈가 64MB기 때문에 전체 디스크에서는 64MB만큼의 공간을 차지합니다. 따라서 이와 같은 불필요하게 공간의 낭비가 계속 일어나는 걸 막기 위해서 블록사이즈는 상한선 개념으로 작동하게 되는 것입니다.
추가적으로 블록사이즈는 청크사이즈와 마찬가지로 자유롭게 설정을 통해 결정할 수 있고, 그 크기는 최대 데이터노드 서버의 스토리지의 크기까지 가능합니다. 데이터노드 서버의 스토리지가 무한하게 크다면, 무한대가 되는것이죠.
(2) 하둡 클러스터에서의 블록
하둡 클러스터 내부에서 HDFS는 저장되는 파일들을 한개 혹은 그 이상의 블록으로 나누고, 각각의 블록을 복제본(Replication) 설정에 따라 복제본을 생성합니다. 디폴트 값은 GFS와 마찬가지로 3입니다.
생성된 모든 원본 블록과 복제본들은 랜덤하게 슬레이브 서버들에 저장됩니다. 마스터 서버에서는 블록들이 저장되지 않고 슬레이브 서버에만 블록들이 저장되는 이유는 마스터 서버의 부하를 최소화 하기 위해서입니다.
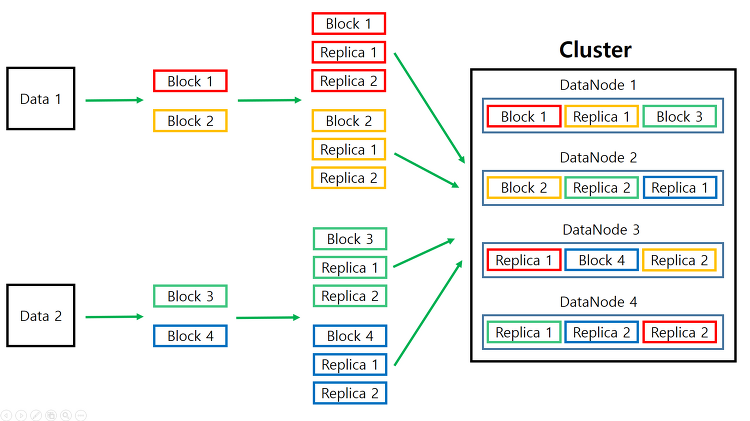
여기서 복제본 생성이라는 말 때문에 조금 헷갈릴 수 있는데, 원본 제외 세 개의 복제본을 생성한다는 개념이 아니라 서로 다른 세 개의 슬레이브 서버에 동일한 블록들을 분산 저장할 수 있도록 복제본을 만든다는 뜻으로 이해해야합니다. 따라서 복제본 설정이 3이라는 건, 위의 그림처럼 원본 블록을 두 개 더 복제해서 서로다른 세 개의 슬레이브 서버에 나누어 저장한다는 것을 의미합니다.
그리고 랜덤하게 저장된다는 건, 별다른 규칙성 없이 같은 블록데이터가 같은 슬레이브 서버에 저장되지 않게끔만 분산 저장하기 때문입니다. 그래서 블록들이 어느 슬레이브 서버에 들어가게 될지 사용자는 알 수도 없고 알 필요도 없습니다. 그저 하둡 클러스터 내부적으로 작동한다는 것을 아는 것 만으로도 족합니다.
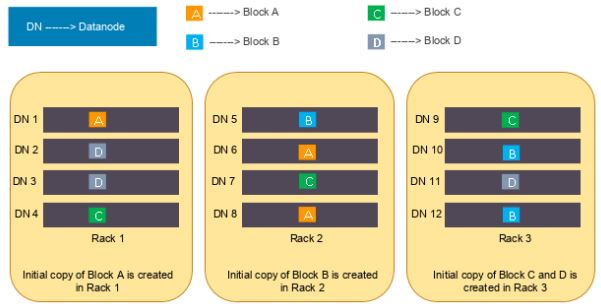
위의 그림은 복제본 설정이 3인 경우에 어떻게 슬레이브 서버에 분산 저장되는 지를 보여줍니다. 원본 블록은 4개이고 복제본 까지 합치면 총 12개의 블록이 만들어집니다. 원본 블록과 복제본은 내부적으로 서로다른 세 개의 슬레이브 서버에 저장됩니다. A블록을 예로 들면, 1번, 6번, 8번 슬레이브 서버에 나누어 저장됐다는 것을 확인할 수 있습니다.
3) 네임노드와 데이터노드
앞선 블록에 대한 내용을 보면, HDFS의 블록들이 어떻게 나눠지고 저장되는지를 알 수 있습니다. 그런데 한가지 궁금해지는게 있습니다.
블록들이 랜덤으로 슬레이브 서버에 저장되고 그 저장되는 위치를 사용자가 몰라도 된다는건 언뜻 납득할 수 있습니다. 그럼 원하는 파일이 있을 때 어떻게 가져와야할까요? 누군가는 알고 있어햐 하지않을까요? 그리고 그 정보를 가지고 있는 건 누구일까요?
이때 등장하는게 바로 앞서 많이 언급된 네임노드와 데이터노드라는 데몬입니다.
(1) 네임 노드
네임 노드에 대해 이야기하기 위해 HDFS의 특징을 하나 살펴보죠.
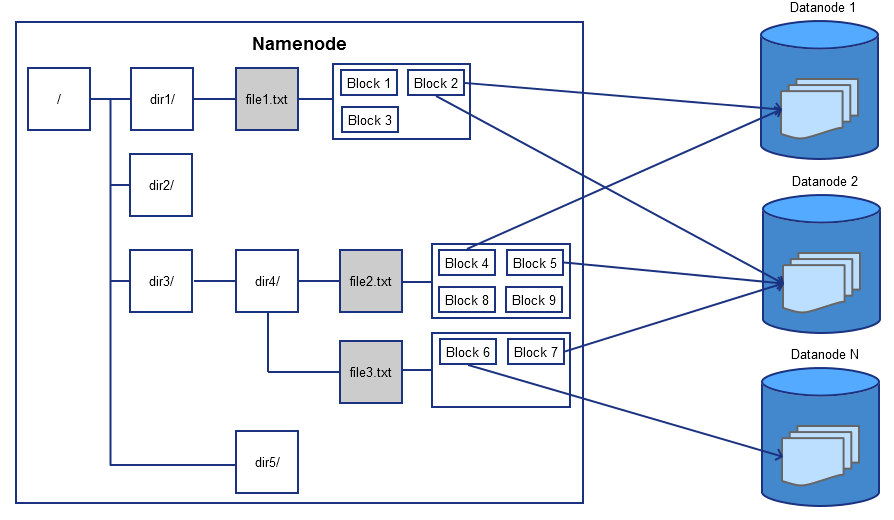
HDFS는 디렉터리 및 파일을 포함하는 계층형 파일 시스템을 사용합니다. 이를 통해 기존 운영 체제에서 사용하는 것과 같은 방식으로 데이터를 파일에 저장할 수 있도록 지원합니다. 사용자는 디렉터리를 만들고 이러한 디렉터리 내에 파일을 저장할 수 있다는 것이죠.
계층적 파일 시스템을 따른다는건 위의 그림처럼 트리 시스템이 있다는 것을 의미합니다. 이는 HDFS를 사용해본 경험이 있으시다면 이해가 바로 되실겁니다. ‘hdfs dfs -mkdir’ 이라는 명령어로 디렉토리를 생성하고 ‘hdfs dfs -put’ 명령어로 그 디렉토리에 파일을 저장해본 경험이 있을테니까요.
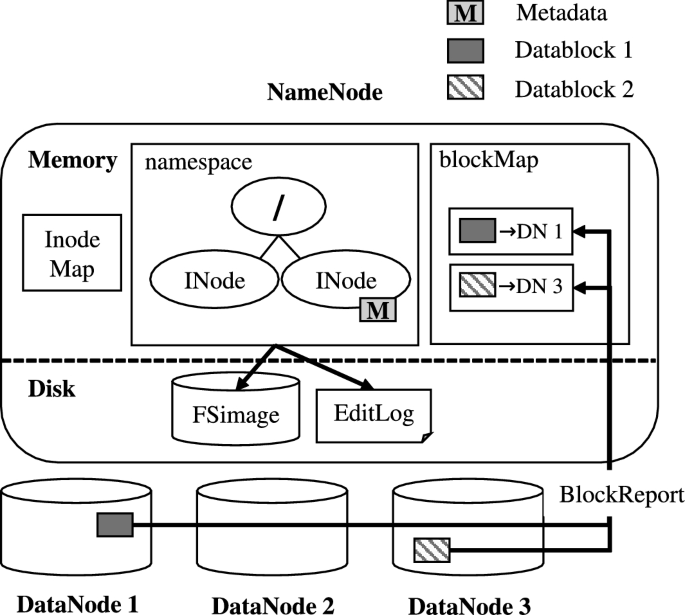
네임 스페이스(NameSpace)
네임노드는 이러한 파일시스템 트리 그 자체와 그 트리에 포함된 모든 파일과 디렉토리에 대한 메타데이터를 네임스페이스를 통해 관리합니다. 여기서 네임스페이스는 파일 또는 디렉토리의 이름, 소유자, 권한 그리고 파일을 구성하는 블록 정보, 블록크기 등을 포함하는 파일시스템 메타데이터가 있는 일종의 컨테이너입니다. (컨테이너라는 말에서 알 수 있듯 실제로 네임스페이스는 도커의 기반이 되는 리눅스의 기능입니다.) 추가로 네임스페이스에는 블록의 위치정보 즉, 어느 블록이 어느 슬레이브 서버에 저장되었는지에 대한 정보가 없다는 것을 기억해두시기 바랍니다.
네임스페이스에서는 파일 및 디렉터리 만들기, 삭제, 수정, 이름변경 등 파일 시스템 상의 작업들을 지원합니다. 그리고 네임노드는 이러한 파일시스템 메타데이터 정보의 모든 변경 사항들을 기록합니다. 이를 위해 네임노드는 자신의 로컬 디스크에 두 개의 영속적인(persistent) 파일을 생성하는데, 첫째는 트랜잭션 로그를 기록하는 Edit Log 파일이고 둘째는 네임스페이스의 이미지를 담은 Fsimage 파일입니다.
Edit Log
우선 Edit log에 대해 이야기 해보도록 하겠습니다.
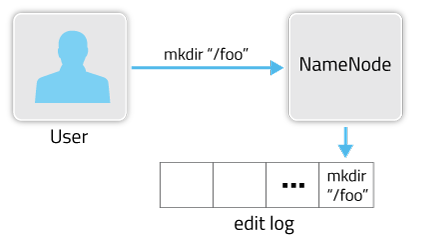
위의 그림은 edit log가 작성되는 방식을 아주 간단하게 도식화한 것 입니다. 여기서 사용자는 네임노드 서버에서 ‘hdfs dfs -mkdir /foo’ 라는 명령어를 통해 hdfs의 루트 디렉토리 밑에 foo라는 디렉토리를 생성했습니다.
새로운 디렉토리가 생겨났다는건 파일 시스템 트리에 변화가 생겼다는 것을 의미합니다. 그래서 네임노드는 이 변화에 대한 것을 기록하려합니다. 이때 사용하는 파일이 Edit log라는 파일입니다. 이 파일안에 foo라는 디렉토리가 생성됐다는 내용이 기록되는 것이죠.
이처럼 네임노드는 Edit log에 새 디렉토리 생성과 같이 파일 시스템 메타데이터에서 발생하는 모든 변경 사항들을 기록합니다. 그러면 이 Edit log는 어디에 사용하는 걸까요?
네임노드는 기본적으로 파일 시스템의 메타데이터를 네임스페이스라는 메모리 공간에 로드하여 in-memory 방식으로 관리합니다. 만약 위의 예시처럼 디렉토리 생성 커맨드가 입력되고 이에 대한 내용이 Edit log에 기입되면, 그제서야 네임노드는 이 변경사항을 네임스페이스에 업데이트합니다.
- 인메모리(in-memory)
- 파일과 메모리 양쪽에 데이터를 유지하는 방식. 여기서 파일은 디스크에 저장된 데이터를 의미하기 때문에 풀어 말하면 ‘디스크와 메모리 양쪽 영역에서 데이터를 유지하는 방식’으로 이해할 수 있다.
이해를 높히기위해서 직전의 내용을 더 깊게 설명해보도록 하겠습니다.
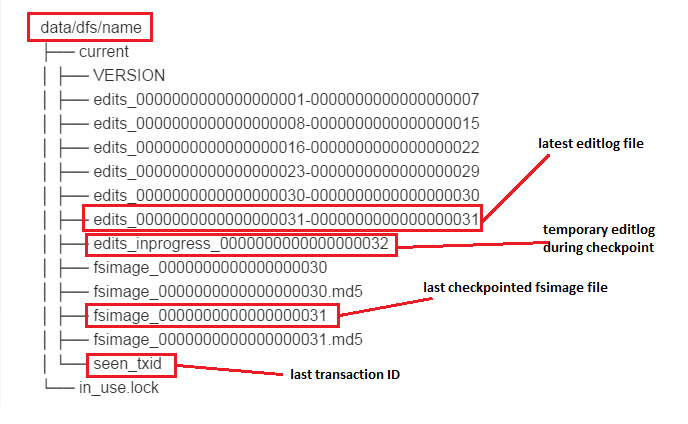
Edit log는 기본적으로 세그먼트(segment) 단위로 관리가 됩니다. 위의 그림에서 볼때 edit + 숫자(’시작 트랜잭션 ID - 끝 트랜잭션 ID’를 의미)처럼 규칙성있는 형태로 저장되어 관리되는 형태를 세그먼트 단위로 관리된다고 이야기하며, 각 파일이 세그먼트가 됩니다.
이 세그먼트들은 쓰기 작업(생성 또는 이동)이 발생할 때, 한번에 하나의 파일만 쓰기 작업을 위해 열립니다. 쓰기 작업을 위해 열린 세그먼트는 오직 그 쓰기 작업을 위해서만 열린다는 이야기입니다.
이 때문에 네임노드는 쓰기 작업이 발생했을 때 edit_inprogress라는 파일에 먼저 작성합니다. 이 파일은 다른 세그먼트들과 다르게 inprogress라는 단어가 추가적으로 붙어있는데, 현재 진행중인 쓰기 작업을 처리하기위해 사용되는 세그먼트임을 나타냅니다. 실제로 edit_inprogress 파일은 사용자가 읽을 수 없도록 되어있습니다.
위의 그림을 보면, edit_inprogress 파일의 트랜잭션 아이디가 32인 것을 알 수 있습니다. 한번에 하나씩 쓰기작업을 한다는게 바로 이것을 의미합니다. 즉, 아직 32번 트랜잭션이 진행중이라는 뜻입니다.
반면, edit로 시작하는 세그먼트들은 이름에서 시작 트랜잭션 ID와 끝 트랜잭션 ID가 ‘-’로 구분되어 나타납니다. 이는 어쨌든 트랜잭션 작업이 끝났고 그것이 완전히 기록되었다는 것을 의미합니다. 이렇게 마무리된 세그먼트는 이후에 수정할 수 없습니다.
edit_inprogress 파일의 동기화 및 플러시는 트랜잭션이 끝나기 전에 수행됩니다. 즉, 클라이언트가 쓰기 작업이 완료됐다는 사실을 전달받기 전에 이루어진다는 이야기입니다. 이렇게 동기화와 플러시가 완료가 되면, 비로소 쓰기 작업도 정상적으로 완료됩니다. 그제서야 네임노드는 Edit log의 변경 사항을 네임스페이스 상의 메타데이터에 업데이트하게 됩니다.
추가적으로 Edit log가 저장되는 디렉토리에 보면 seen_txid라는 파일과 VERSION이라는 파일이 있는데, seen_txid는 마지막으로 닫힌 세그먼트의 최종 트랜잭션 ID를 저장하는 파일이고 VERSION은 Edit log의 메타데이터를 보유하고 있는 파일입니다.
Fsimage(File-system image)
fsimage를 한마디로 정의하면, 파일시스템 메타데이터의 영속적인 체크포인트 파일이라고 할 수 있습니다.
사실 fsimage의 정의를 이해하기위해선 edit log 파일이 작성된 후 네임스페이스의 파일시스템 메타데이터가 변경된다는 사실을 리마인드할 필요가 있습니다.
fsimage는 개념적으로 네임스페이스의 스냅샷(Snap shot)입니다. 이는 특정 시점(트랜잭션을 기준으로 함)에서의 네임스페이스에 대한 모든 정보가 fsimage파일에 저장되어있기 때문입니다.
그런데 이상한 점은 Edit log가 계속 네임스페이스에 반영되는 동안에도 fsimage 파일은 변화가 일어나지않는다는 겁니다. 그럼 도대체 언제 edit log 파일과 fsimage파일이 합쳐질까요?
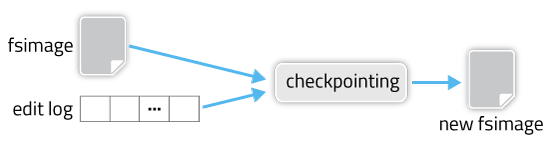
fsimage는 네임노드에 장애가 발생하거나 재시작할 때, edit log 파일과 통합되어 새로운 fsimage가 만들어지고 이전에 존재하던 fsimage는 fsimage.ckpt라는 파일로 변경됩니다.
좀 더 자세한 이야기를 해보죠.
edit log는 기본적으로 fsimage가 만들어진 이후에 발생하는 트랜잭션들을 기록합니다. 더 정확히는 fsimage가 생성되는 그 텀에서 발생하는 트랜잭션을 기록하는 것이죠. 실제로 가장 처음에 만들어진 fsimage는 아무내용도 적혀있지 않은 상태로 있습니다.
그렇게 edit log는 하둡클러스터가 작동하는 동안 계속 쌓이다가 네임노드에 장애가 발생하거나 재시작할 때, 기존의 네임스페이스를 edit log를 사용하여 갱신합니다. 그리고 갱신된 네임스페이스를 가지고 다시 fsimage파일을 새로이 생성합니다. 그 이후 edit log는 삭제됩니다.
네임노드 재시작 시, 네임스페이스 구성(갱신) 순서
- 기존의 fsimage를 메모리에 불러와 읽고
- edit log도 불러와서 읽은 후,
- edit log의 내용을 반영하여 갱신된 네임스페이스를 구성한다.
- 갱신된 네임스페이스의 스냅샷을 찍어 새로운 fsimage파일을 생성하고,
- 기존의 fsimage파일은 fsimage.ckpt로 변경한다.
- 마지막으로 기존의 edit log는 삭제한다.
다시말하면, fsimage는 네임스페이스가 새로이 갱신된 바로 그 시점에 네임스페이스에 저장된 파일시스템 메타데이터를 그대로 저장하게 되는 것 입니다. 이 때문에 fsimage를 체크포인트 파일이라고 부르고 이러한 과정 전체를 일컬어 체크포인팅이라고 하게 됩니다.
그런데 여기서 궁금한 것이 하나 생깁니다. 만약 네임노드에 아무런 장애도 발생하지 않고 재시작도 하지않으면 어떻게 될까요?
Edit log, 정확히는 현재 작업중인 세그먼트(edit_inprogress)는 스토리지만 무한하다면, 이론상 무한히 커질 수 있습니다. 사실 네임노드가 구동중인 상태라면 별 상관은 없지만(물론 로컬 디스크 보다 커져버리면 문제가 됩니다), Edit log가 엄청나게 커진 상태에서 네임노드를 재시작 했다고 생각하면 어떨까요?
네임노드는 재시작되면서 체크포인팅을 하기 위해 edit log파일과 fsimage파일을 검색 할겁니다. 그런다음 기존 fsimage와 edit log파일로 네임스페이스를 갱신하고, 이 갱신된 네임스페이스의 스냅샷을 새로운 fsimage 파일로 만들겠죠.
근데 edit log의 파일이 너무 크면, 네임노드가 구동되는 순간부터 모든 과정이 매우 느려지게 됩니다. 네임노드는 그 거대한 edit log를 메모리에서 모두 읽고 그 모든 내용을 네임스페이스에 갱신시키고, 이 갱신된 네임스페이스로 새로운 fsimage를 만들어서 로컬 디스크에 저장해야하기 때문이죠. 게다가 새로운 fsimage 파일 자체도 상당히 클 것이고, 그 큰 edit log 파일을 삭제하는 시간도 만만치는 않을 겁니다.
실제로 하둡 클러스터를 운영중에 edit log파일이 너무 커지는 바람에 재가동 과정에서 장애가 발생한 케이스는 심심치 않게 찾아볼 수 있을 정도입니다.
이처럼 Edit log가 관리하기 힘들정도로 커지는 것을 방지하기 위해서 HDFS는 Secondary namenode라는 특수한 노드를 사용합니다. Secondary NameNode는 현재 작업중인 세그먼트를 정기적으로 롤백하여 주기적인 체크포인팅을 수행하는 마스터 데몬입니다. 해당 단락은 네임노드와 데이터 노드에 관한 이야기이기 때문에 이 이상의 자세한 설명은 별도로 하겠습니다.
Block Map
위에서 봤던 그림을 다시 한번 가져와 보죠.
이제까지는 네임스페이스와 그와 관련된 두 개의 파일(FSimage& Edit log)에 대한 내용이였습니다. 그러니 이젠 네임노드의 또다른 요소인 Block Map에 대해 이야기해볼 차례입니다.
혹시 앞에서 네임스페이스에서는 블록의 위치에 대한 정보는 들어있지 않다는 점을 아직 기억하고 있다면, 바로 이 Blcok Map에서 네임스페이스가 가지고 있지 않던 블록 위치 정보가 보관되고 있습니다.
데이터노트 파트에서 더 자세하게 설명하겠지만, 데이터노드는 네임노드에게 정기적으로 Heartbeat와 Block report를 보냅니다. 이 중 block report에는 각 데이터노드들이 관리하고 있는 블록 정보들이 담겨 있는데 네임노드는 이를 받아 자신이 가지고 있던 block ID와 매핑하여 블록 위치정보를 가지게 됩니다. 그리고 이를 메모리 상에 올려놓고 클라이언트의 요청이 발생하면 즉각적으로 응답할 수 있도록 합니다.
블록 위치 정보는 네임스페이스에 저장된 다른 메타데이터와 달리 디스크에 별도의 파일로서 저장되진 않습니다. 대신, 매번 네임노드가 재시작될 때마다 일괄적으로 데이터노드로 부터 블록 정보를 받아 매핑하는 작업이 이루어집니다. 이렇게 한번 Block Map이 구축되고 나면, 그 때부터 block report를 통해 업데이트가 이뤄지게 되는 것입니다.
여기서 날카로운 분들은 ‘그럼 block ID는 어디서 가져오는건데?’라고 물어보실 수 있습니다. 그리고 이에 대한 답변은 ‘네임노드는 블록들의 ID를 지정하고 그 블록들이 저장될 데이터노드 서버를 할당하는 역할을 수행한다’는 말로 대신할 수 있습니다.
쓰기작업이 일어난 예시를 통해 하나씩 풀어서 이야기 해보도록하죠.
우선 하둡 클러스터를 사용하고자하는 사용자가 있습니다. 그 사용자는 클라이언트 서버를 통해 쓰기 작업을 하고싶다고 요청합니다. 이 때 클라이언트는 사용자가 설정한 블록 크기에 맞춰 파일을 블록단위로 쪼갭니다. 즉, 하둡 자체적으로 들어온 파일은 블록단위로 쪼갠다는 이야기입니다. 그리고 하나 더 기억해야할 건 복제본은 여기서 만들어지지 않는다는 사실입니다.
이후 클라이언트는 네임노드에게 사용자가 설정한 블록 크기와 복제본 수에 대한 내용을 전달하고, 네임노드는 블록과 복제본을 저장할 수 있는 데이터 노드 서버를 할당한 후 이 정보를 클라이언트에게 반환합니다. 가령 블록 A는 데이터노드 서버 1, 3, 6번에 저장하도록하는 일종의 리스트로 말입니다. 일종의 특정 블록과 저장될 데이터노드 서버들이 매핑된 리스트의 개념이라고 할 수 있죠.
동시에 네임노드는 각 블록을 파일 시스템 계층에 추가합니다. 더 나아가자면 각 블록에 대한 이름, 크기, ID 그리고 파일을 구성하는 블록 정보 등을 자신의 네임스페이스에 보관합니다. 이는 추후 클라이언트의 요청시 빠르게 관련 파일을 찾을 수 있도록하기 위함입니다.
클라이언트는 네임노드로 받은 정보를 데이터 노드에게 전달합니다. 클라이언트는 원본 블록만 가지고 있기 때문에 그 원본 블록을 네임노드가 전달해준 것들 중 하나의 데이터 노드에 저장하면, 데이터노드는 클라이언트가 같이 준 리스트를 참조해서 자신과 같은 리스트에 속하는 다른 데이터노드의 서버에 복제본을 생성합니다. 만약 레플리카가 3개로 설정되어 있다면 다른 2개의 데이터노드의 서버에 복제본이 만들어지겠죠.
이러한 복제의 과정은 연쇄적으로 일어납니다. 그래서 특별히 이 과정을 일컬어 Replication Pipeline이라고 부르기도합니다.
클라이언트가 데이터 노드 서버 1번에 블록을 저장하면, 데이터노드 1번은 데이터노드 3번 서버에 복제본을 생성합니다. 그리고 데이터노드3번은 그다음인 데이터노드 서버 6버에 복제본을 생성합니다. 이렇게 복제본의 생성이 완료되면, 데이터 노드들은 해당 작업이 완료됐음을 네임노드에게 알립니다. 그리고 작업이 완료됐음을 전달받은 네임노드는 edit log에 기록 후 클라이언트에게 작업 완료 메세지를 반환하는 것으로써 전체 쓰기 작업이 종료됩니다.
사실 실제 메커니즘은 이보다 훨씬 더 복잡합니다. 다만, 여기서 어떻게 block id가 설정되는 지에 대한 감을 잡을 수 있다면 충분하다고 생각합니다. HDFS에서 실제 쓰기 작업과 읽기작업이 어떤 방식으로 일어나는지는 번외편으로 작성하도록 하겠습니다.
INode Map
INode Map은 특정 경로에 해당하는 inode를 빠르게 찾아 반환하기 위해 메모리상에 존재합니다.
그럼 inode는 뭘까요?
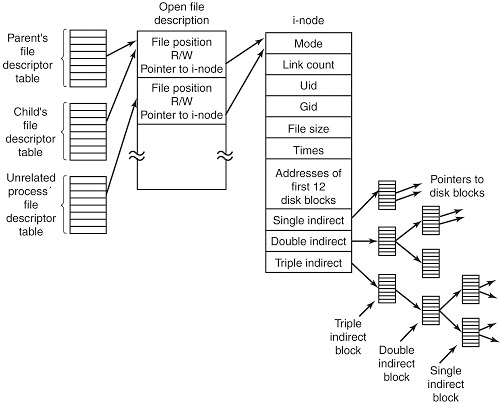
inode는 Unix/Linux의 파일 시스템에서 사용되는 자료구조를 말합니다. 파일 시스템 계층에 존재하는 모든 디렉토리와 파일들은 고유한 inode를 하나씩 가지고 있습니다.
각 inode는 파일의 복제 단위, 변경 및 접근시간, 접근권한, 블록 크기와 파일을 구성하는 블록 조합들 같은 정보를 가집니다. 사실상 우리가 이제껏 말했던 메타데이터는 바로 이 inode에 담겨있는 것이죠.
inode는 파일 시스템에 존재하는 모든 파일과 디렉토리는 고유한 inode를 갖기 때문에, 실제 파일 시스템 계층 구조를 표현할 때 파일 이름이나 디렉토리 이름대신 inode를 사용합니다. 실제로 네임스페이스를 이야기할 때 본 그림을 보면, 네임스페이스 안에서 파일 시스템 계층을 루트(/) 아래에 inode로 표현하고 있습니다.
이는 inode가 그 자체로 인덱스의 역할을 수행하기 때문인데, 리눅스/유닉스 시스템은 이 inode라는 특수한 인덱스를 통해 훨씬 빠르게 원하는 파일이나 디렉토리에 접근하여 정보를 받아 낼 수 있습니다.
결국 네임노드는 네임스페이스에서 더 빠르게 원하는 파일의 메타데이터를 조회하기 위해 Inode Map을 메모리 상에 올려놓고 사용하는 것입니다.
(2) 데이터노드
기나긴 네임노드에 관한 이야기가 드디어 끝이 났습니다.
마스터의 부하를 최소화하는 구조로 HDFS를 구성해야한다는 이야기를 납득하지 못했던 분들이라면 앞선 과정을 거치면서 왜 마스터의 부하는 최소화 되어야하는 지를 납득하지 않았을까하는 생각이 듭니다.
본론으로 들어가보죠.
마스터노드가 전체 HDFS를 관리하는 역할이라면, 데이터노드는 실질적인 일꾼입니다. 이러한 데이터노드의 역할을 하나씩 나열하면서 살펴보도록하겠습니다.
우선 데이터노드는 실질적으로 파일을 관리합니다. 좀더 명확하게는 블록을 관리하죠. 데이터 노드가 관리하는 블록들은 해당 데이터노드가 실행중인 로컬 파일 시스템에 저장이 됩니다.
데이터노드는 네임노드가 (재)시작할 때, 자신의 로컬 파일 시스템에 저장된 블록들을 스캔하여 해당 정보를 네임노드에게 전달합니다. 이는 네임노드가 block map을 구성하기 위한 절차입니다.
이뿐만 아니라 데이터노드는 HDFS가 작동하는 동안에는 자신이 가진 블록들을 주기적으로 스캔하여 네임노드에게 전송하기도 합니다. 이를 block report라고 합니다. block report에는 데이터노드가 관리하는 block id들이 담겨있습니다. 네임노드는 이를 주기적으로 받아 block map을 업데이트하게 됩니다.
근데 만약 블록 스캔 과정에서 블록이 손상됐다는 것을 인식한다면 어떻게 될까요?
클라이언트는 블록을 만들 때 각 블록의 체크섬(checksum)을 계산하고 이를 자신의 네임스페이스의 공간에 저장해 둡니다. 그리고 각 데이터 노드는 주기적인 스캔과정에서 자신들이 가진 블록과 checksum이 일치하는지를 검증하는 블록 스캐너를 실행합니다.
만약 클라이언트가 전체 블록을 읽고 체크섬 검증이 성공했다면, 이를 데이터 노드에게 알리고 데이터노드는 이를 검증된 것으로 간주합니다. 그리고 해당 블록을 제공해줍니다.
데이터노드는 블록의 검증 시간을 로그 파일로 자신들의 로컬 디스크에 저장합니다. 그리고 각 데이터노드는 검증 시간 순으로 된 스캔한 블록 리스트를 메모리에 올려둡니다. 스캔이 완료된 목록에 대한 요청이 들어오면 해당 블록을 제공해주기도 하고, 정기적으로 정상적인 블록의 목록을 block report에 담아 네임노드에 전송합니다.
클라이언트나 블록 스캐너가 손상된 블록을 발견하면 그 사실을 바로 네임노드에 알립니다. 네임노드는 해당 복제본을 손상됐다고 마킹합니다. 단, 블록삭제를 바로 진행하진 않습니다. 대신, 손상되지않은 블록으로 새로운 복제본을 만들고 난 후에 삭제합니다.
데이터노드는 block report외에도 heartbeat를 주고받습니다. 이는 네임노드가 데이터노드의 health condition을 확인하기 위한 일종의 메세지입니다. 네임노드는 주기적으로 데이터노드에게 heartbeat를 보내도록 하고 데이터노드는 이에 따릅니다. 만약 일정시간 이상 heartbeat가 오지 않으면 네임노드는 해당 데이터노드가 장애가 생긴것으로 판단하여 장애 복구절차를 수행합니다.
데이터노드는 블록의 생성, 삭제 및 복제와 같은 작업을 직접 수행합니다. 이러한 작업들은 네임노드의 지시를 받아서 진행하게 되는데, 이는 예시를 통해 설명해보죠.
블록 A가 저장되어있는 데이터노드 서버가 네트워크 장애로 클러스터와의 연결이 끊긴 상황을 가정해보죠.
우선 기본적으로 클러스터가 유지해야하는 레플리카는 3개라고 하겠습니다. 그런데 블록A가 저장된 서버에 장애가 생기면, 네임노드는 해당 데이터노드로부터 hearbeat를 받지 못하게 됩니다. 이로인해 네임노드는 블럭A의 존재를 인식할 수 없게 되죠.
이때 네임노드는 복제본 3개를 유지하기 위한 절차를 수행하게 됩니다. 우선 남아있는 블록A의 복제본들이 있는 서버 하나를 찾아서 해당 서버의 데이터노드에게 새로운 블록A 복제본을 다른 데이터노드 서버에 생성하도록 지시합니다. 이로써 하둡 클러스터는 블록 A의 개수를 유지할 수 있게됩니다.
그런데 만약 클러스터 관리자가 장애가 났던 서버를 복구시키면 어떻게될까요?
이 경우엔 블록A가 클러스터 내에서 4개가 존재하게 되는 상황이 발생해버립니다. 이때 네임노드는 복제본 3개를 유지하기 위한 또다른 절차를 밟습니다. 이는 당연히 하나의 블록A를 삭제하는 것이겠죠.
4) Secondary NameNode
지난 Edit log와 Fsimage에서 간단하게 언급했었던 세컨더리 네임노드(Secondary Namenode)에 대해 이야기 해보겠습니다.
사실 세컨더리 네임노드를 처음 본사람이면, 뭔가 네임노드가 문제가 생겼을 때 그 역할을 대신해줄 수 있는 녀석인가하고 생각할겁니다. 실제로 저는 그렇게 생각했었습니다.
근데 세컨더리 네임노드는 네임노드의 보조적인 역할만을 수행합니다. 기능적으로 네임노드를 완전히 대체할 수는 없다는 것이죠.
그럼 하둡은 왜 세컨더리 네임노드가 필요했던 것일까요?
Edit log가 너무 커지면, 이를 로드하는 과정에서 네임노드 서버의 장애가 발생할 수 있습니다. 네임노드는 재시작할 때마다, 네임스페이스 재구성을 위해 edit log와 fsimage파일을 읽도록 설계되어 있기 때문이죠. 그리고 만약 이 과정에서 네임노드가 장애가 발생한다면, 전체 하둡 클러스터의 문제로 이어질겁니다. 왜냐면 네임노드는 SPOF(단일 실패 지점)이니까요.
그래서 하둡은 이러한 문제를 극복하기 위해 Fsimage 파일의 복사본을 백업하고 로그파일을 편집할 수 있는 세컨더리 네임노드를 구현했습니다. 즉, edit log의 크기를 가능한 한 작게 유지하여 리스크를 줄이고 싶었고, 혹시 모를 네임노드 서버의 디스크 장애에 대비해 다른 서버에 백업본을 유지하고 싶었다는 것이죠.
이로인해 세컨더리 네임노드는 크게 백업과 체크포인트라는 두가지 역할을 맡고 있습니다. 사실 체크포인트 프로세스에 백업이 포함되어 있습니다. 다만 역할에 대한 쉬운 이해를 위해 잠깐만 분리해서 접근하겠습니다.
우선 백업역할에 대해 이야기 해보겠습니다. 세컨더리 네임노드는 네임노드가 가지고 있는 fsimage파일을 자신의 로컬로 가지고 와서 저장합니다. 그리고 세컨더리 네임노드는 edit log도 주기적으로 가져옵니다. 이 행위 자체가 두 파일을 백업한 것이죠.
그 다음은 체크포인트입니다. 직전 내용에서 세컨더리 네임노드는 fsimage파일과 edit log 파일을 자신의 로컬로 가져온다고 이야기 했습니다. 그 이후 세컨더리 네임노드는 두 파일을 자신의 메모리상에서 병합(merge)시킨 후 새로운 fsimage파일을 만들어 이를 네임노드로 보냅니다. 네임노드는 기존 fsimage를 세컨더리 네임노드로 부터 받은 새로운 fsimage 파일로 교체합니다. 이러한 과정을 일컬어 체크포인트(또는 체크포인트 프로세스 또는 체크포인팅)라고 합니다.
동시에 네임노드는 edit log 파일도 초기화합니다. 이미 fsimage에 edit log가 반영되어 있어 기존의 edit log는 불필요 해졌기 때문이죠.
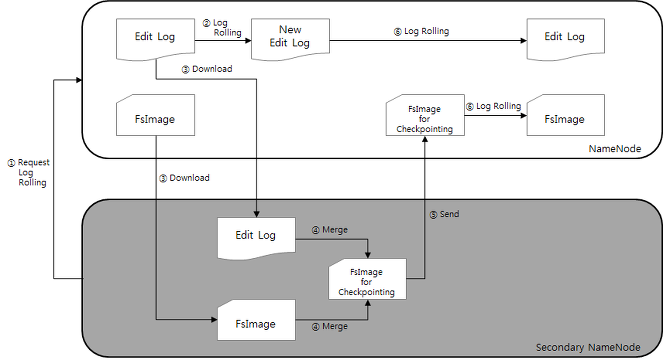
세컨더리 네임노드는 경과 시간과 트랜잭션 수 라는 두 가지의 트리거 조건이 존재합니다. 이는 설정값으로 변경할 수 있습니다.
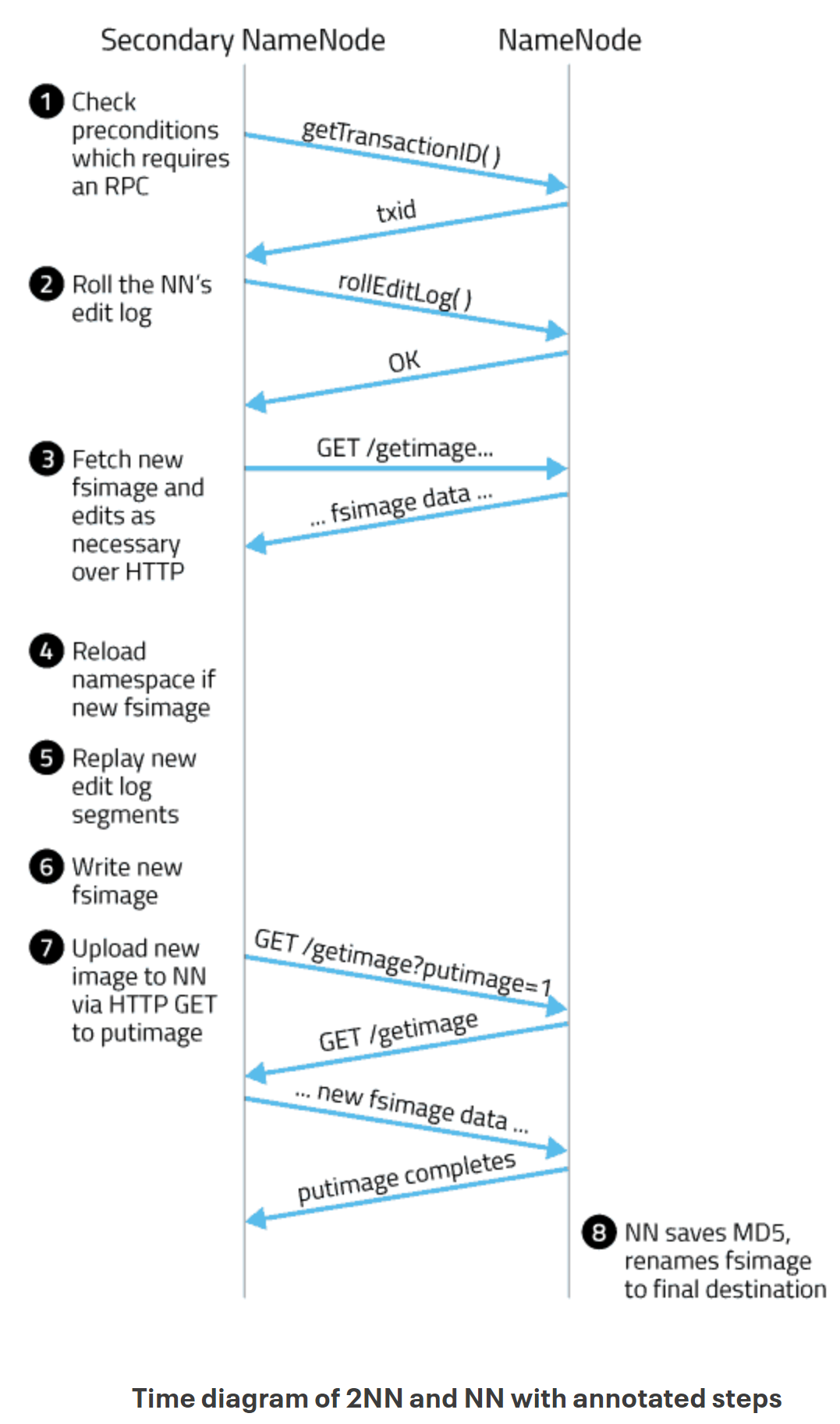
경과시간은 어느정도의 시간간격으로 체크포인트 작업을 실행 시킬건지이며, 트랜잭션 수는 Edit log가 어느정도의 트랜잭션을 기록하면 체크포인트 작업을 진행시킬건지를 결정하는 설정을 의미합니다(디폴트 값은 각각 1시간과 백만개). 이중 하나의 조건라도 충족되면, 위의 그림과 같은 절차로 체크포인트 프로세스가 실시됩니다.
위의 그림을 기준으로 체크 포인트 프로세스를 간단히 설명하자면,
- 세컨더리 네임노드에서 네임노드에게 로그 롤링을 요청하여 edits.new라는 초기화 파일을 생성
- 네임노드의 fsimage와 edits를 세컨더리 네임노드의 로컬 파일 시스템으로 가져옴
- 세컨더리 네임노드의 메모리에서 두 파일을 읽고 병합하여 fsimage.ckpt라는 파일로 생성
- fsimage.ckpt 파일 네임노드에 전송
- fsimage.ckpt와 edits.new 파일을 로그 롤링하여 edits와 fsimage로 생성
사실 조금 이보다 더 복잡한 메커니즘이 있긴합니다. RPC 통신을 한다던지 세컨더리 네임노드가 네임노드로 부터 fsimage와 edit log를 가져올 때는 HTTP GET을 이용해서 가져온다던지, 새로운 fsimage를 네임노드로 보낼때는 HTTP POST를 사용한다던지와 같은 것들 말이죠.
이러한 추가적인 내용은 밑의 그림을 통해 이해하시면 될 것 같습니다.
3. HDFS의 특징
1) 블록(데이터)의 지역성(Locality)
HDFS 하에서 파일은 기본적으로 블록으로 나눠지고, 원본 블록과 복제본들은 서로다른 데이터노드 서버에 분산 저장됩니다.
전통적인 분산 시스템은 스토리지에서 데이터를 프로세서로 이동함으로써 시간 낭비가 심했습니다. 하둡은 이 문제를 해결하기 위해 데이터 지역성(Data locality)을 통해 데이터를 처리하는 방법을 택했습니다. 파일을 나누어 각각의 서버가 파일을 읽어 들이고, 가능하다면 저장되어 있는 노드에서 데이터를 처리한다는 것이죠.
데이터 지역성을 확보함으로서 얻는 이득은 크게 세가지 입니다.
- 네트워크를 이용한 데이터 전송 시간 감소
- 대용량 데이터 확인을 위한 디스크 탐색 시간 감소
- 적절한 단위의 블록 크기를 이용한 CPU 처리시간 증가
이 개념은 사실 맵리듀스와 함께 이해하는 것이 좋긴합니다.
맵리듀스는 HDFS의 데이터 지역성을 이용해서 처리 속도를 증가시킵니다. 처리 알고리즘이 있는 곳에 데이터를 이동시키지 않고, 데이터가 있는 곳에서 알고리즘을 처리하여 네트워크를 통해 대용량 데이터를 이동시키는 비용을 줄일 수 있습니다.
블록 지역성을 위한 작업 우선 순위는 다음과 같습니다.
- 같은 노드에 있는 데이터
- 같은 랙(Rack)의 노드에 있는 데이터
- 다른 랙의 노드에 있는 데이터
2) 블록 캐싱
데이터 노드에 저장된 데이터 중 자주 읽는 블록은 블록 캐시(block cache)라는 데이터 노드의 메모리에 명시적으로 캐싱할 수 있습니다. 파일 단위로 캐싱 할 수도 있어서 조인에 사용되는 데이터들을 등록하여 읽기 성능을 높일 수 있습니다.
3) Rack Awareness
Rack Awareness의 컨셉은 블록의 복제본들이 어디에 저장되어야할지 결정하는 것 입니다.
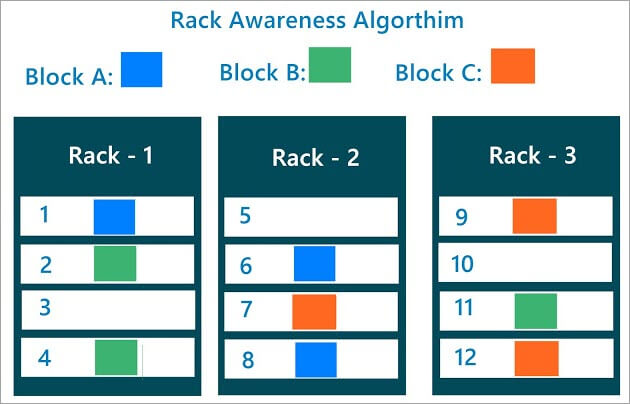
위의 그림은 Rack Awareness가 일어나는 알고리즘을 표현한 그림입니다. 위의 그림에서 하둡 클러스터는 3개의 Rack과 12개의 데이터노드로 구성되어 있고, 복제본 설정은 3개로 되어 있습니다.
같은 블록의 복제본들은 Rack 기준으로 2개씩 들어가 있도록 구성되어 있습니다. 그리고 나머지 하나만 다른 Rack에 들어가 있습니다.
Rack Awareness 알고리즘이 바로 이런식으로 작동하는 것입니다. 우선적으로 두개의 복제본을 같은 Rack에 있는 데이터노드에 분산하여 저장하고, 나머지 하나는 같은 Rack에 저장하지 않고 다른 Rack에 보내는 방식으로 작동한 다는 것입니다.
결국 Rack Awareness는 HDFS가 Rack 단위의 장애를 대비하기 위한 안전장치의 개념입니다. 만약 Rack 전원이나 스위치 등에 문제가 생겼다고 생각해보면, 한 Rack 모든 블록 복제본이 있다는건 그 블록의 유실을 의미하기 때문입니다.
Rack Awareness는 하둡의 사용자/관리자가 직접 설정을 통해 조정할 수 있습니다. 하둡의 관리자는 수동으로 클러스터의 각 슬레이브 노드의 Rack 번호를 정의해주게 됩니다.
4) HDFS 세이프 모드
HDFS의 세이프 모드는 데이터 노드를 수정할 수 없는 상태를 말합니다. 세이프 모드가 되면 데이터는 읽기 전용 상태가 되고, 데이터 추가나 수정이 불가능하며, 데이터 복제도 일어나지 않습니다.
세이프모드가 작동되는 경우는 크게 세가지로 나눠볼수 있습니다.
첫째, 관리자가 서버 운영 정비를 위해 일시적으로 세이프 모드를 거는 경우입니다. 하둡 사용자/관리자는 명령어를 통해 강제적으로 네임노드가 세이프모드상태로 되게 할 수 있습니다. 보통 이런 경우라면, 서버 정비를 위한 경우가 대부분일 것입니다.
둘째, 네임노드에 문제가 생겨서 정상적인 동작을 할 수 없을 때, 자동으로 세이프 모드로 전환된 경우입니다.
이는 주로 missing block이 발생한 경우에 해당합니다. 앞선 이야기들 중에, 특정 데이터 노드 서버에 네트워크 연결이 끊겨서 네임노드가 클러스터 내 복제본 수를 유지하기위해 새로운 복제본을 생성하도록 했던 사례(Under duplicated)에 대입해보면 이해가 쉽습니다. 네임노드가 복구작업을 하는 동안은 세이프 모드가 되는 것입니다.
셋째, 네임노드가 처음 구동될 때, fsimage와 edit log를 읽어서 메모리에 네임스페이스를 구성하고 데이터노드들로부터 block report를 받아 메모리에 blockMap을 구성하는 동안 세이프 모드가 작동하는 경우입니다. 네임스페이스와 BlockMap가 전부 구성되기 전까지는 세이프 모드가 유지됩니다.
만약 HDFS 운영 중에 세이프 모드로 전환된것을 확인한 경우에는 반드시 네임노드의 문제인지 데이터 노드의 문제인지 파악이 필요합니다.
fsck 명령어로 HDFS의 무결성을 체크하고, hdfs dfsadmin -report 명령으로 각 데이터 노드의 상태를 확인하여 문제를 확인하고 해결한 후 세이프 모드를 해제해야 합니다.
5) 커럽트(Corrupt) 블록
커럽트 블록은 데이터 블록 자체에 문제가 생긴 것을 일컫습니다.
기본적으로 HDFS는 하트비트를 통해 데이터 블록에 어떠한 문제가 있는지를 주기적으로 체크하고 발견시 자동으로 복구하는 시스템을 갖추고 있습니다. 자주 예를 들었던 데이터 노드의 네트워크 연결이 끊기면 네임노드가 이를 감지하고 복제본 수를 유지하기위해 다른 데이터 노드에게 새로운 복제본을 생성할 것을 지시하는 상황이 이에 해당합니다.
그런데 모든 복제 불록에 문제가 생겨서 복구할 수가 없다면, 이는 커럽트 상태라고 합니다. 이때 사용자/관리자는 커럽트 상태의 파일들을 체크한 뒤 삭제하고, 원본 파일을 다시 HDFS에 저장해야합니다.
물론 커럽트 블록이 발생하는 사례는 상당히 드뭅니다. 모두 다른 서버에 저장된 데이터 블록들이 한번에 유실되는건 비범한 사례이니까요.
최근 카카오 IDC 센터가 화재로 인해 마비됐던 사례가 커럽트 블록들이 발생된 사례라고 볼 수도 있습니다. 물론 상세한 내용은 카카오 내부 관계자들만 알테니 섵부르게 이야기하는 걸지도 모르겠습니다만, 중요한건 카카오처럼 예상치 못한 재해들로 IDC 센터들이 문제가 생기지 않는 한 보통의 서비스 작동 중에 발생하긴 어렵다는 사실입니다.
6) 휴지통 기능
HDFS는 휴지통 기능을 지원합니다. HDFS 상에서 파일들을 지웠다고해도 그것들이 즉각적으로 HDFS 내에서 사라지지않도록 휴지통을 설정할 수 가 있습니다.
휴지통의 경로는 /user/사용자명/.trash이고, 이 .trash 디렉토리에 들어있는 파일들은 언제든 복구할 수 있습니다.
휴지통 디렉토리(.trash)는 사용자/관리자가 설정한 간격으로 체크포인트가 실행되며, 설정된 기간이 지나면 영구히 삭제됩니다. 보통 하루에서 많게는 3일정도의 보관기간을 갖도록 설정하는 것이 일반적입니다.
영구삭제가 완료되면 유휴공간으로 반환됩니다.
7) 하둡 운영자 커맨드 - dfsadamin
하둡은 운영자 커맨드가 별도로 존재합니다. 주로 실행이나 설정 관련 명령어가 많습니다.
| 커맨드 | 비고 |
|---|---|
| namenode | 네임노드 실행 |
| datanode | 데이터 노드 실행 |
| secondarynamenode | 세컨더리 네임노드 실행 |
| balancer | HDFS 밸렁싱 처리 |
| cacheadmin | 자주 읽는 데이터에 대한 캐쉬 처리 |
| crypto | 암호화 처리 |
| dfsadmin | HDFS 관리를 위한 Admin 유틸리티 명령 |
| dfsrouter | HDFS 연합 라우팅 실행 |
| dfsrouteradmin | 데이터 노드 라우팅 설정 |
| haadmin | HA 실행 명령어(QJM 또는 NFS) |
| journalnode | QJM을 이용한 HA, 저널노드용 명령어 |
| mover | 데이터 마이그레이션용 유틸리티 명령어 |
| nfs3 | NFS3 게이트웨이 명령어 |
| portmap | NFS3 게이트웨이 포트맵 명령어 |
| storagepolicies | HDFS 저장정책 설정 명령어 |
| zkfc | 주키퍼 FailOver 컨트롤러 실행 |
이중 몇가지 자주 쓰이는 커맨드에 대해서 알아보겠습니다.
- dfsadmin -report : HDFS의 각 노드들의 상태를 출력하며, HDFS의 전체 사용량과 각 노드의 상태를 확인 할 수 있는 명령어. 이 명령어를 통해 알 수 있는 정보는 아래와 같습니다.
- Configured capacity : 각 데이터 노드에서 HDFS에서 사용할 수 있게 할당된 용량
- Present Capacity : HDFS에서 사용할 수 있는 용량
- DFS Remaining : HDFS에서 남은 용량
- DFS Used : HDFS에서 남은 용량
- DFS Used% : 사용중인 용량 %
- Under replicated block : 블록 리플리카 설정보다 블록개수가 적은 블록 수
- dfsadmin -safemode : 세이프 모드에 진입하거나 빠져나올 수 있는 명령어. 사용가능한 옵션은 아래와 같습니다
- -get : 세이프모드 상태를 확인
- -enter : 세이프모드 진입
- -leave : 세이프모드 복구
- -wait : 세이프모드이면 대기하다가, 세이프모드가 끝나면 회복
- dfsadmin -setQuota : 특정 디렉토리에 용량 Quota를 설정하는 명령어. 단위는 bytes이고 사용할 수 있는 옵션은 아래와 같습니다.
- -setSpaceQuota : Quota 설정
- -cirSpaceQuota : Qouta 설정 해제
8) HDFS Balancers
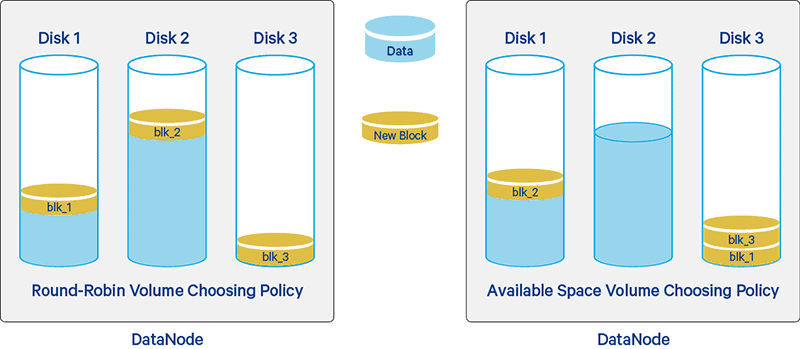
하둡 클러스터를 운영하다보면 서로 다른 스펙의 데이터노드를 하나의 클러스터로 구성하는 경우가 있습니다. 시작부터 스펙이 상이한 서버들로 하는 경우도 있겠지만, 보통은 하둡클러스터 내의 데이터노드를 추가할 때 도입 시기에 따라 서로 상이한 스펙으로 구성될 수 있습니다. 같은 하둡 클러스터라고 해도 2011년에 도입했던 데이터 노드 서버와 2022년에 도입한 데이터 노드 서버의 스펙이 상이할 수 있다는 겁니다.
이 경우 노드 간 디스크 크기의 차이는 전체 데이터의 불균형을 초래할 수 있습니다.
네임노드는 HDFS 상에 데이터 적재될 때, 적재량이 낮은 데이터노드에 우선적으로 블록을 넣는 메커니즘을 가지고 있습니다. 이로인해, 유난히 디스크의 크기가 큰 데이터노드가 있다면 그 노드에 I/O가 집중되면서 성능 저하가 발생할 수 있습니다.
동시에 사용율이 높은 데이터노드라도 데이터가 적재되지 않는것은 아니기때문에, 해당 데이터노드의 디스크가 임계치에 도달해버리면 MapReduece, Hive, Hbase 등이 정상적으로 동작하지 않을 수 있습니다.
이외에도 새로운 노드나 디스크를 추가하는 경우, 대량의 데이터를 삭제하는 경우에도 데이터 불균형이 발생합니다.
따라서 사용자/운영자는 HDFS 밸런스를 조정하는 작업을 수행해야합니다. 물론 이는 2.0대 버전까지이고 3.0부터는 좀 이러한 부분들이 용이할 수 있도록 개선이 되긴합니다.
하지만 운영중인 하둡 클러스터에 대하여 이러한 밸런싱 작업을 수행한다는 건 꽤나 위험한 작업입니다. 하둡 클러스터를 운영한다는건 기본적으로 하둡 클러스터 내에 엄청나게 큰 데이터들이 있다는 것을 의미하고, 동시에 그 거대한 데이터들에 대한 여러 작업들이 24시간 수행되고 있다는 것을 의미하기 때문입니다.
즉, 기본적으로 상단한 리소스를 잡아먹고있다는 것이죠. 그런데 동시에 밸런싱 작업도 상당히 많은 리소스를 잡아먹기때문에, 기존의 작동중인 작업들에 영향을 최소한으로 미칠수 있도록 적당한 리소스를 배분하는 것은 상당히 중요한 문제입니다. 이와 관련된 하둡 밸런싱 옵션은 아래와 같습니다.
| 옵션 | 설명 |
|---|---|
| -policy | blockpool/datanode 중 하나의 정책으로 hdfs balance를 수행한다. ‘datanode’는 각 노드들의 사용량을 balancing하는 것이라면, blockpool은 각 node의 pool까지 balancing하는 것이다. 기본값은 datanode이다. |
| -threshold | 1.0~100.0 사이의 수를 입력하여 어느 정도까지 노드간 밸런싱을 수행할 것인지를 설정한다. 기본값은 10으로 각 노드들을 10% 미만으로 차이가 날 때까지 밸런싱을 수행한다 |
| -blockpools | HDFS가 명시된 리스트의 BOLCKPOOL만 밸런싱 수행한다. 만약 리스트가 비워져 있다면 모든 blockpool을 밸런싱한다. 기본값은 공백이다. |
| -include -f | 밸런싱을 수행할 호스트를 명시한다. -f옵션으로 호스트들의 리스트를 가지고 있는 파일을 지정하던가, 콤마로 구분된 여러 호스트들을 지정한다. 만약 공백이라면 모든 데이터노드에 대해서 진행하며 기본값을 공백이다. |
| -exclude -f | -include 옵션과 반대로 밴런싱에서 제외할 호스트들만을 입력한다. 공백값은 어떠한 노드들도 제외되지 않는 것이고 기본값은 공백이다. |
| -idleiterations | HDFS Balancer가 더이상 밸런싱할 블록이 없을 때까지 반복적으로 Balancer를 수행한다. 기본 값은 5인데, 이동할 블록이 없더라고 5번의 검사를 진행한다. |
| -runDuringUpgrade | 만약 이 옵션이 추가되어 있다면 HDFS 업그레이드 수행중에 Balancer를 수행한다. 하지만 일반적으로 권고되지 않는 방법이다. 지속적으로 삭제되는 HDFS 블록들이 HDFS 내부 trash 공간을 빠르게 채우기 때문이다. |
더 자세한 내용은 여기서 확인 할 수 있습니다.
마지막으로 하둡 파일 설정(hdfs-site.xml) 중 Balancer와 연관된 중요한 설정들이 있습니다.
1
2
3
4
5
6
7
8
9
10
11
# in hdsf-site.xml
<property>
<name>dfs.datanode.balance.max.concurrent.moves</name>
<value>50</value>
</property>
<property>
<name>dfs.datanode.balance.bandwidthPerSec</name>
<value>104857600</value>
</property>
첫째는 동시에 얼마나 빠르게 복사를 할 것인가와 관련된 옵션입니다. 쓰레드를 여러개 띄워서 밸런싱을 할때, 얼마나 많은 쓰레드가 밸런싱 작업을 수행하도록 할 것인지를 결정하는 것입니다.
둘째는 데이터노드 기준으로 bandwidth를 얼마나 줄것인지와 관련된 옵션입니다. 기본적으로 데이터노드끼리 서로 블록들을 주고받으면서 밸런싱이 이루어지기 때문에, 트래픽이 발생하게 됩니다. 이때 트래픽을 처리하기위해 초당 어느정도의 bandwidth을 설정할 것인지를 해당 설정에서 조정 가능합니다.
보통 Balancer와 관련된 설정들은 상당히 보수적/방어적으로 설정하는 경우가 일반적입니다. 이는 위에서도 말했듯 리소스를 너무 많이 잡아먹어서 기존의 작업들에 영향을 크게 미치는 등 전체 하둡 클러스터 운영에 끼칠 악영향을 우려하기 때문입니다.
이로인해 밸런싱 작업은 조금씩, 그리고 상당히 오랜기간에 걸쳐 진행되는 경우가 많습니다. 클러스터 규모에 따라 다르지만 길게는 한달씩 걸리기도 합니다.
사실 이런 복잡한 밸런싱 문제들로 인해서 가장 바람직한 하둡 클러스터는 디스크의 용량이 크게 차이가 안나는 노드들로 구성하는 것입니다. 물론 현실의 문제 속에서 그러기에는 쉽지 안습니다.
9) Web HDFS REST API
HDFS는 REST API를 사용하여 파일을 조회하고, 생성, 수정, 삭제하는 기능을 제공합니다. 물론 이를위해 하둡 설정이 필요합니다.
자세한 내용은 공식 홈페이지에서 확인할 수 있습니다.
10) HDFS 암호화 -KMS(Key Management Server)
하둡 KMS는 KeyProvider API를 기반으로 하는 암호화 키 관리 서버입니다. Key Management Server라는 별도의 서버를 띄워서 암호화를 진행합니다.
HDFS의 암호화 과정은 특정 디렉토리를 암호화지역으로 설정하여, 발급된 암호화키로 이용할 수 있도록 합니다.
이때문에 서버를 띄우기위한 기초적인 설정들이 필요합니다. 가령 어떤 암호화 방식을 사용할건지, 퍼블릭키는 어떤 것을 사용할 것인지 등을 설정해줘야합니다.
자세한 내용은 공식 홈페이지에서 확인할 수 있습니다.