지난 포스팅들에서도 자주 언급했지만 하둡 2.0은 가장 굵직한 변화가 있었던 버전입니다.
네임노드의 이중화를 통한 고가용성(HA) 아키텍쳐 도입, Yarn도입을 통한 리소스 관리 및 스케쥴링 기능 등이 대표적인 예죠.
해당 포스트는 HDFS의 기능에 초점을 맞추고 있기때문에 HDFS가 하둡 2.0에서부터 어떠한 변화들이 있었는지에 초점을 맞춰 하나씩 살펴보도록 하겠습니다.
1. 네임노드의 이중화
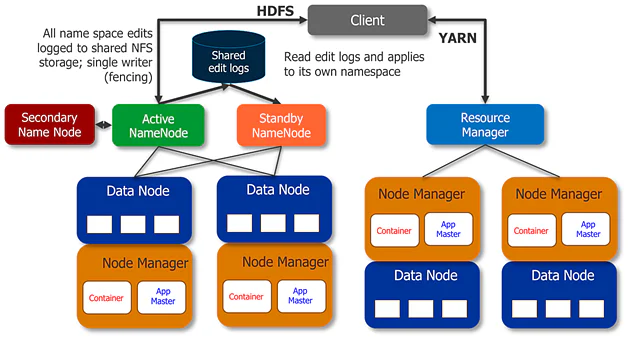
하둡 2.0버전에 들어서 가장 큰 변화가 무엇인지 꼽으라면 단연 네임노드의 이중화입니다.
GFS부터 HDFS 초기버전까지는 단일 마스터와 다수의 슬레이브 구조를 따랐습니다. 이는 마스터가 다운되면 전체 클러스터가 다운되어버린다는 아주 치명적인 문제가 있었죠. 이를 일컬어 마스터가 단일 장애 지점(SPOF, Single Point Of Failure)이기 때문에 발생하는 가용성의 부족 문제라고 합니다.
가용성은 시스템이 장애없이 얼마나 오래지속가능한지에 대한 것 입니다. HDFS처럼 마스터가 단일 장애 지점이면, 마스터의 장애만으로도 전체 시스템의 장애로 확산되기때문에 단일 마스터 구조는 가용성이 부족하다고 하는 것이죠.
이러한 문제를 해소하기 위해 하둡은 2.0버전부터 네임노드의 이중화를 지원합니다. 아주 직관적으로 네임노드 하나로만 클러스터를 구성하지 않고 예비용 네임노드까지 추가하여 클러스터를 구성한다면, 마스터가 단일 장애 지점이 아니게 되니 고가용성 아키텍쳐를 구성할 수 있다고 본 것이죠.
1) Active-Standby NameNode
하둡 2.0버전에서는 네임노드의 이중화를 위해 두 종류의 네임노드를 사용합니다. 하나는 Active 다른 하나는 Standby라고 부르죠.
Active 네임노드는 그 이름에서 알 수 있듯이 현재 네임노드의 역할을 수행하고 있는 네임노드를 말합니다. 반면, Standby 네임노드는 예비용으로 대기하고있는 네임노드입니다.
Active 네임노드가 장애로인해 다운될 시, Stanby 네임노드는 Active 네임노드로 격상되어 기존의 Active 네임노드가 하던 작업들을 그대로 인계합니다.
이러한 네임노드의 이중화 구조를 위해서 두 네임노드는 물리적으로 분리되어있습니다. 같은 서버에 두 데몬을 띄우는건 이전과 다를바가 없이 단일 장애 지점이 되기때문이죠.
사실 이처럼 네임노드를 두 개로 구성한다는 발상자체는 단일 장애 지점에 대한 정말 심플한 해결법을 제공합니다. 그런데 네임노드의 이중화는 몇 가지 이유로 인해 쉽게 해결할 수 있는 문제는 또 아닙니다.
한번 생각해보죠.
Active 네임노드 서버가 다운되었을 때, Standby 네임노드가 이를 고스란히 인계해야하는데 이를 위해선 Standby 네임노드는 Active 네임노드와 동일한 네임스페이스를 구성해야합니다. 이는 Active 네임노드 서버에 저장된 fsimage와 edit logs 파일이 Standby 네임노드 서버에도 동일하게 있어야함을 의미하죠.
그런데 Active 네임노드 서버가 다운되었는데 어떻게 Standby 네임노드 서버로 fsimage와 edit log 파일을 가져올 수 있을까요?
그리고 Active 서버가 다운되면, Standby 네임노드는 어떻게 장애를 인지할 수 있을까요? 만약 장애를 잘못인지하여 한 클러스터에 두개의 Active 네임노드가 구성되는 상황이 생긴다면 그때는 어떻게 해야 할까요? 또한 이처럼 Active 네임노드가 중복되는 상황을 방지하려면 어떻게 해야할까요?
실제로 하둡은 이러한 문제들로 인해 1.0버전과 2.0버전 사이에 꽤나 긴 기간이 존재합니다. 이 부분에 대한 해결방안을 위해 긴시간 고민을 했다는 것이죠. 그렇게 하둡은 앞선 의문들에 대해 몇가지 옵션을 활용해 해결할 수 있는 방안을 제시했습니다.
그것이 바로 Edit log 공유와 주키퍼의 사용입니다.
2) Shared Edit logs
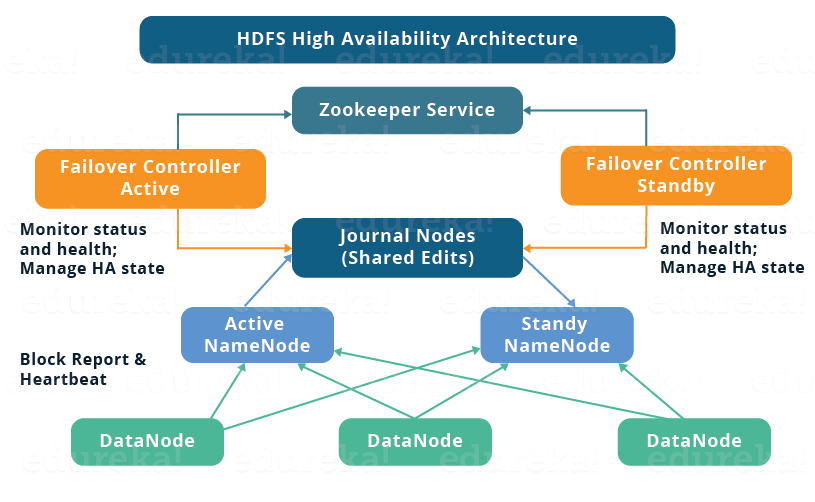
네임노드의 이중화에서 가장 핵심이 되는 부분을 꼽으라면 바로 이 Edit logs의 공유입니다. 실제로 하둡 2.0을 선보이기 전까지 가장 많은 이슈가 있었다고 전해지는 부분이죠.
기본적으로 이중화된 네임노드들은 위의 그림처럼 클러스터 내의 데이터노드와 연결되어 있습니다. 즉, Active와 Standby네임노드 모두 데이터노드들로부터 Block report와 Heartbeat를 받고 있다는 것이죠.
이때문에 데이터노드들의 정보를 종합하는 작업에는 문제가 없습니다. 다만, 문제는 바로 네임스페이스를 구성하기 위한 Fsiamge와 Edit log 파일을 어떤방식으로 공유할 것인가였죠.
하둡은 두 네임노드 간 Edits 정보를 공유하기 위해 기존의 네임노드 로컬 디스크에서 보관하던 방식에서 벗어나, 외부에 Edits 정보를 적재하여 공유하는 방식을 선택했습니다. Edit 정보를 공유하는 방식은 크게 두 가지로 구분되는데, 첫째는 NFS방식인 NAS를 사용하는 방법이고 둘째는 JournalNode라는 새로운 시스템을 도입하는 것이였습니다.
NFS방식 : NAS 사용
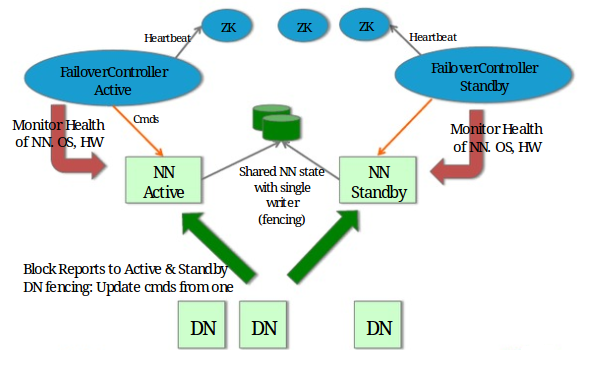
fsimage와 edit log 파일을 공유하는 가장 쉬운방법은 NAS와 같은 공유 스토리지를 이용하는 방법입니다.
1.0버전부터 네임노드는 설정을 통해 두 파일을 원하는 디렉토리를 지정하여 저장할 수 있었고, 심지어 콤마를 사용해서 다수의 디렉토리를 지정하는 것도 가능했습니다.
하둡은 이를 활용해 외부에 새로운 디스크를 네크워크로 네임노드들과 연결해 fsimage와 edit log 파일을 저장하는 공유 스토리지(Shared Storage)로 사용하도록 했습니다. 쉽게 생각하면 네트워크 상에서 외장 디스크를 연결하여 이를 공유 스토리지로 사용했다는 것이죠.
- NAS(Network Attached Storage)
- 스토리지를 네트워크에 부착하여 네트워크에 기반한 데이터 공유방식
이렇게 스토리지 문제는 간단하게 해결이 가능하지만, 문제점이 남아있었습니다.
가령 장애를 잘못인식하여 클러스터 내의 Active 네임노드가 중복되는 상황이 발생하는 경우가 대표적입니다.
분산 시스템 환경에서는 이 처럼 메인 시스템이 쪼개져서 별도로 작동하는 경우를 Split brain이라고 부릅니다. Split brain은 네트워크 단절로 인한 통신 장애가 원인인 경우가 대부분이지만, 하둡과 같은 고가용성 시스템에서는 두개의 Activce 네임노드가 활성화되는 경우를 포함합니다.
Split brain 상황에서는 두 Active 네임노드는 동시에 Edit log를 공유 스토리지에 작성하게 됩니다. 각자가 자신의 Edit log를 작성하다보면, 필연적으로 두 네임 노드가 작성한 Edit log 간의 충돌이 발생하는데 이는 데이터의 무결성과 일관성을 손상시키는 결과를 초래합니다.
이때문에 하둡은 Split brain 문제를 방지하기 위해 주키퍼라는 도구를 사용하여 자동으로 장애를 인지하고 Active 네임노드와 Standby 네임노드가 전환되도록 했습니다.
그러나 이렇게 주키퍼를 이용하여 자동으로 장애 상황을 확인하여 펜싱처리할 경우에도 여전히 문제가 남아 있었습니다. 아주 드문 경우긴하지만, Active 네임노드가 주키퍼와 Standby 네임노드와의 네트워크는 단절되었지만 공유 스토리지와는 여전히 통신이 되는 상황이 바로 그것이죠.
1
2
3
4
5
💡 펜싱(fencing) ≒ Stonith(shoot the other node in the head)
: 이전의 Active 네임노드가 현재 네임스페이스의 내용을 바꾸지 못하도록 보장하기위한 하둡의 기술. HDFS는 아래와 같은 다양한 펜싱 메커니즘을 사용하고 있습니다.
- 이전의 Active 네임노드 종료
- NFS 명령을 사용하여 공유 스토리지 디렉토리에 대한 해당 네임노드의 엑세스 권한 취소
- 해당 네임노드에 대한 네트워크 비활성화
이 상황에서는 여전히 Split brain 문제가 발생할 가능성이 남아있습니다. Active 네임노드에 장애가 발생하면, Standby 네임노드에서 펜싱처리는 네트워크 단절로 인해 수행할 수 없는데 기존 Active네임노드는 여전히 live한 상태를 유지하기 때문입니다.
따라서 이처럼 공유 스토리지를 사용하여 fsimage와 edit log파일을 공유하는 방식으로 네임노드 이중화를 구성하는 것은 안정적인 failover 처리에 한계가 있어 잘 사용하지 않게 되었습니다.
그래서 이런 문제점을 해결하기위해서 하둡은 JournalNode라는 것을 제공합니다.
QJM 방식 : JournalNode 사용
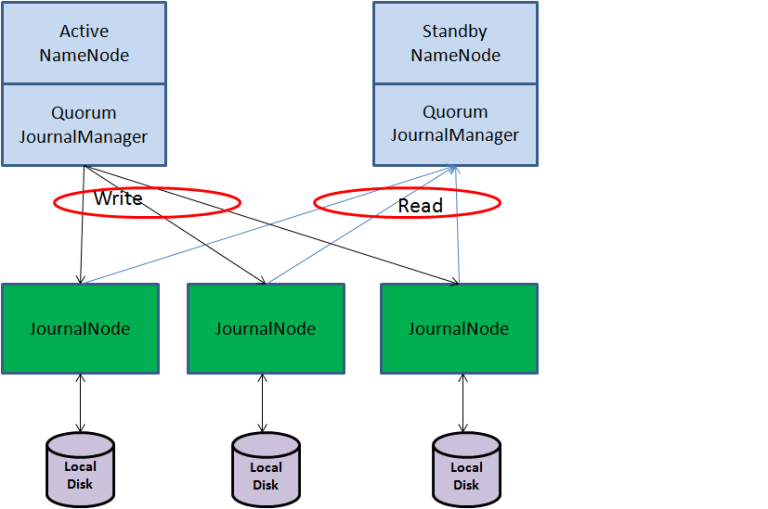
보통 하둡에서 고가용성 클러스터를 구축한다고 하면, 저널노드(JournalNode)를 사용한 구성을 말합니다. 즉, NAS와 같은 방식으로 공유 스토리지를 사용하지 않고 저널노드를 사용하는 방식은 하둡 자체만으로 고가용성 아키텍쳐를 구성할 수 있는 디폴트 방식입니다.
QJM(Quorum Journal Manager)은 네임노드 내부에 구현된 HDFS 전용 구현체입니다. 바로 위의 그림처럼 저널노드로 네임노드 이중화를 구성하게 되면, 이를 QJM 방식이라고 합니다.
좀 풀어서 보면, QJM을 위한 구성요소는 두 개의 네임노드와 홀수개의 저널노드입니다. QJM은 기본적으로 고가용성 Edit log를 지원하기 위한 목적으로 설계되었기 때문에 이 부분에 초점을 맞춰서 이해해야 합니다.
저널노드
저널노드는 edits 정보(파일 시스템의 journaling 정보)를 저장하고 공유하는 기능을 수행하는 데몬입니다.
저널노드에 저장되는 데이터는 하둡 입장에서 아주 중요한 데이터이기 때문에 보통 하나의 서버로 구성하지 않고, 최소 3대이상의 홀수개의 서버로 구성하는 것이 일반적입니다. 그래서 저널노드 그룹이라고 통칭해서 부르기도 합니다.
그런데 굳이 저널노드만을 위한 서버를 만들지는 않습니다. 기본적으로 저널노드는 리소스를 적게 차지하기 때문에 네임노드 서버, 스탠바이 네임노드 서버, 잡트래커 서버 등과 같은 마스터 서버에서 같이 실행시키는게 일반적입니다.
저널노드는 기본적으로 Active 네임노드만 저널노드에 edit 정보를 작성할 수 있도록 합니다. 이는 위에서 언급했던 두 개의 Active 네임노드가 동시에 edit log를 작성하면서 발생하는 Split brain문제를 없애기 위해서입니다.
또한 각 Edit log는 전체 저널 노드에 동시에 쓰여지게 됩니다. 이는 네트워크 장애로 인해 발생하는 Split brain 시나리오에 대응하기 위해서 입니다.
모든 저널노드에 동시에 Edit log를 저장하기 때문에 일부 저널노드가 네트워크 장애 등으로 Split brain 문제가 발생하더라도 이에 따른 파일들의 손상에 대비할 수 있게 됩니다.
두 개의 네임노드
QJM 하에서 두 개의 네임노드는 모두 저널노드를 통해 FSimage와 Edit log를 공유합니다. 그리고 이를 통해 두 네임노드가 각자 자신의 네임스페이스를 구성하고 있습니다.
Stanby 네임노드는 JournalNode에서 주기적(통상 1분)으로 Edit log의 변경 사항을 확인하고 변경사항이 있을 시, 이를 읽고 자신의 메모리에서 네임스페이스를 업데이트합니다. 하둡 1.0버전에서 세컨더리 네임노드가 수행하던 역할을 Standby 네임노드가 자신의 네임스페이스에서 별도로 수행하고 있다고 생각하면 됩니다.
동시에 두 네임노드는 모두 데이터노드들과 연결되어 Block report와 heartbeat를 받고있기 때문에, 동일한 blockMap을 구성합니다.
이처럼 Standby 네임노드는 언제든 Active 네임노드로 전환할 준비가 되어있기 때문에, Active 네임노드의 장애 발생 시 빠른 failover 절차가 가능해집니다.
물론 현실적인 상황에서 즉각적으로 전환이 이루어지지는 않습니다.
실제로 하둡 2.0에서는 Failover 과정에서 Standby 네임노드가 Active 전환되면서 약간의 다운타임이 존재합니다.
이는 네임스페이스에 들고있는 데이터의 양이 얼마나 되냐에 따라 달려있는데, 보통 수억개의 파일(100GB 이상)에 대한 네임스페이스를 구성했다고 할때, 5~10분정도의 다운타임이 존재한다고 합니다.
이러한 미흡합에도 이전의 1.0에서 마스터가 단일 장애 지점일 때보다는 훨씬 진일보된 아키텍쳐임에는 이견이 없습니다.
다만 한가지 기억해야할 것은 QJM은 Edit 정보의 고가용성 아키텍쳐를 구성할 뿐, 실제 Active 네임노드들의 장애를 감지하거나 Standby 네임노드를 Active로 전환시키는 작업을 수행하진 않습니다.
즉, Active 네임노드가 장애가 난 경우에도 시스템이 Active 네임노드에서 Standby 네임노드로 failover를 자동으로 트리거하지 않습니다.
보통 이 failover 자동화를 위해 주키퍼를 사용하지만, 기본적으로 주키퍼를 사용하지않는 네임노드 이중화는 하둡 클러스터 관리자가 Active 네임노드의 장애를 인지하면, 직접 dfsadmin 커맨드를 활용하여 Standby네임노드를 Active 네임노드로 전환시키는 수동 failover 방식을 사용합니다.
2. Zookeeper
고가용성 하둡 클러스터에서 자동 failover를 구현하기 위해서는 두 가지 새로운 구성요소를 추가해야하는데 이는 각각 주키퍼 쿼럼(Zookeeper Quorum)과 ZKFC(ZookeeperFailoverController)입니다.
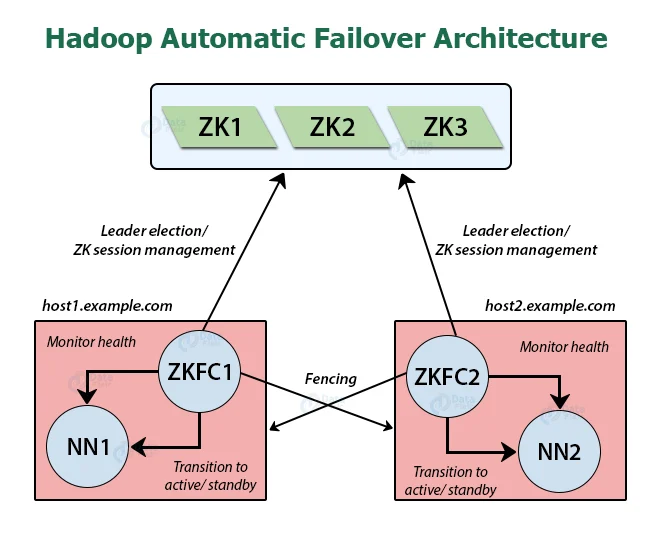
주키퍼 쿼럼(Zookeeper Quorum)
주키퍼는 클러스터 내의 데이터들을 유지 관리하고, 클라이언트에게 해당 데이터의 변경 사항을 알리고, 클라이언트의 오류를 모니터링하기 위한 고가용성 서비스입니다.
보통 주키퍼 데몬은 3개 또는 5개의 노드에서 실행되도록 구성되는데 이는 QJM가 3개 이상 홀수개의 저널노드를 사용하는 것과 같은 이유이기 때문에 주키퍼 쿼럼이라는 말을 사용합니다. (사실 정확하게는 주키퍼 쿼럼이라는 말이 훨씬 먼저 사용되었고, 이후 QJM이라는 용어를 탄생시키는데 영향을 미친것입니다.)
주키퍼 데몬은 저널노드처럼 리소스를 많이 사용하지 않기 때문에 별도의 서버 대신 네임노드와 같은 기존의 마스터서버들에서 같이 실행시키는것이 일반적이라는 사실까지 비슷합니다.
HDFS는 자동 Failover를 구현하기 위해 두 가지 측면에서 주키퍼에 의존하고 있습니다.
우선 첫째, 장애 감지입니다. 기본적으로 주키퍼는 ZKFC를 통해 네임노드들과 세션을 유지하고 있습니다.
만약 Active 네임노드와 연결된 ZKFC의 반응이 없으면, 세션이 끊긴것으로 간주하고 주키퍼는 바로 Standby 네임노드에게 Active 네임노드에 장애가 났음을 알립니다.
그러면 Standby 네임노드에서 Failover가 트리거 되어 Active 네임노드로 전환됩니다. 이 과정에서 기존의 Active 네임노드는 펜싱처리됩니다.
둘째, Active 네임노드 선출입니다. 주키퍼는 네임노드를 Active로 선택하는 간단한 메커니즘을 가지고 있습니다. 즉, Standby 네임노드 중 어떤 것을 Active 네임노드로 선출할지가 주키퍼의 리더 선출 기능에 의해 정해진다는 것입니다.
하둡 2.0에서는 Standby 네임노드가 하나이기 때문에 큰 의미는 없지만 이후 다룰 하둡 3.0에서부터는 다수의 Standby 네임노드로 클러스터를 구성할 수 있기 때문에 기억해둘 필요가 있습니다.
이외에도 주키퍼는 기본적으로 단 하나의 네임노드만 Active 상태에 있는 것을 보장합니다. 이는 주키퍼가 평소에 ZKFC를 통해 네임노드와 세션을 유지함으로서 이루어집니다.
ZKFC(ZookeeperFailoverController)
ZKFC는 네임노드의 상태를 모니터링하고 관리하는 주키퍼 클라이언트입니다. 이를 위해 ZKFC는 네임노드가 실행되고 있는 서버에서 같이 데몬으로 동작합니다.
ZKFC는 주기적으로 자기와 같은 서버에 위치한 네임노드에게 신호를 보내고, 네임노드가 정상 상태로 적시에 응답하는 한 해당 네임노드를 정상으로 간주하고 주키퍼와의 세션을 유지합니다.
반대로 해당 네임노드가 충돌, 정지 등의 사유로 다운되면, ZKFC는 해당 네임노드를 비정상이라고 표시하고 주키퍼와의 세션을 종료합니다.
그러면 세션이 끊김을 인식한 주키퍼가 자신이 선출한 Standby 네임노드와 연결된 ZKFC에게 Active 네임노드의 장애가 발생했음을 알리고, ZKFC는 이를 받아 자신의 로컬에 위치한 Standby 네임노드에게 Failover를 트리거 시킵니다.
Standby 네임노드의 메타데이터의 동기화가 완료되면, ZKFC는 해당 네임노드를 Active 네임노드로 전환시키고, 기존의 Active 네임노드를 펜싱시킵니다.
이를 통해 ZKFC는 클러스터에 단 하나의 Active 네임노드가 존재하는 것을 보장합니다.
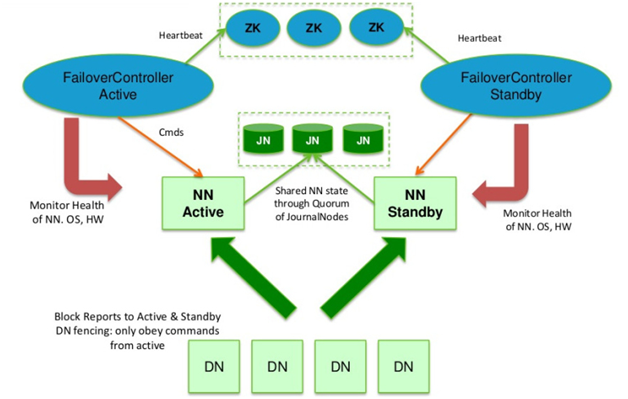
결론적으로 위의 그림과 같이 주키퍼와 QJM을 사용해 하둡 고가용성 클러스터를 구축했을 때의 Failover 세부 절차는 아래와 같습니다.
1
2
3
4
5
6
7
8
9
10
11
💡 JournalNode 사용 시, Failover 절차
1. Active NameNode는 edit log 처리용 epoch number를 할당 받는다. 이 번호는 uniq하게 증가하는 번호로 새로 할당 받은 번호는 이전 번호보다 항상 크다.
2. Active NameNode는 파일 시스템 변경 시 JournalNode로 변경 사항을 전송한다. 전송 시 epoch number를 같이 전송한다.
3. JournalNode는 자신이 가지고 있는 epoch number 보다 큰 번호가 오면 자신의 번호를 새로운 번호로 갱신하고 해당 요청을 처리한다.
4. JournalNode는 자신이 가지고 있는 번호보다 작은 epoch number를 받으면 해당 요청은 처리하지 않는다.
a. 이런 요청은 주로 SplitBrain 상황에서 발생하게 된다.
b. 기존 NameNode가 정상적으로 Standby로 변하지 않았고, 이 NameNode가 정상적으로 fencing 되지 않은 상태이다.
5. Standby NameNode는 주기적(1분)으로 JournalNode로 부터 이전에 받은 edit log의 txid 이후의 정보를 받아 메모리의 파일 시스템 구조에 반영
6. Active NameNode 장애 발생 시 Standby NameNode는 마지막 받은 txid 이후의 모든 정보를 받아 메모리 구성에 반영 후 Active NameNode로 상태 변환
7. 새로 Active NameNode가 되면 1번 항목을 처리한다.
여기서 1~7번은 QVM에 의한 작동이고, Failover가 트리거 되는 과정과 6번 중 Active 네임노드로 전환되는 부분이 주키퍼에 의한 작동이라고 보면 됩니다. 추가로 Active 네임노드로 전환되는 과정에는 당연히 이전의 Active 네임노드를 펜싱하는 과정이 포함됩니다.
이러한 절차를 거쳐 자동적으로 failover가 이루어지기 때문에, 갑작스러운 장애가 발생하더라도 Standby 네임노드가 자연스럽게 Active 네임노드로 전환되고, edit log 파일의 손상 문제도 발생하지 않게 됩니다.
3. HDFS Federation
네임노드는 파일 시스템 메타데이터를 메모리 상에서 관리합니다. 대략 백만 블록당 1GB 정도의 메모리가 사용됩니다.
그런데 하둡 클러스터를 운영하다보면 파일 시스템 상의 파일이 점점 많아지면서 메모리 사용량이 늘어나고, 이로 인해 메모리 관리에 대한 이슈가 발생할 수 있습니다.
이를 해결하기 위해 하둡 2.0부터 HDFS 페더레이션이라는 기능을 추가했습니다.
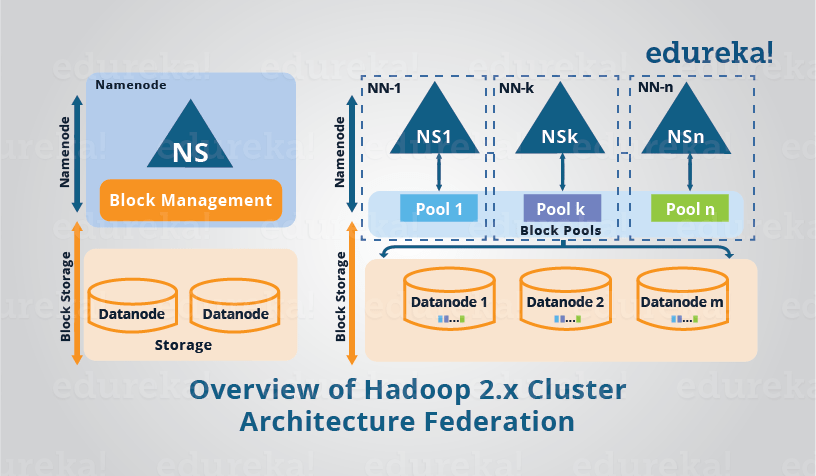
하둡 2.0이전의 버전에서는 전체 클러스터에 대한 단일 네임스페이스만 허용합니다. 이 구성에서 단일 네임노드는 단일 네임스페이스를 관리합니다.
하지만 2.0버전부터 지원되는 HDFS 페더레이션은 HDFS에 디렉터리 단위로 네임노드를 등록하여 사용합니다.
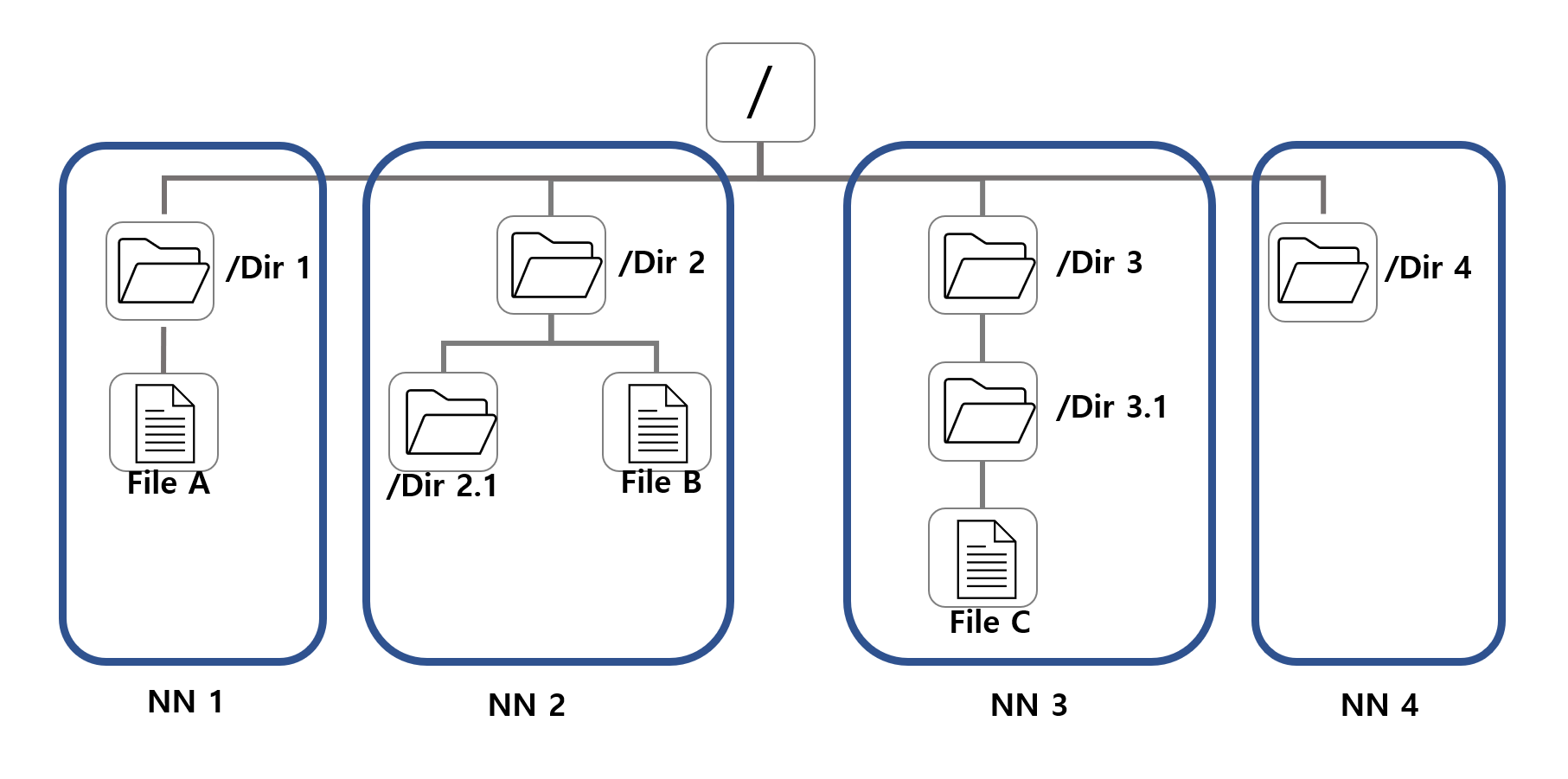
이를 이해하기 위해서는 HDFS가 계층형 파일 시스템이라는 것을 다시한번 상기해볼 필요가 있습니다. 더 정확히는 네임스페이스에는 HDFS의 계층형 파일 시스템 메타데이터가 저장되어 있다는 사실을 말입니다.
HDFS 페더레이션의 핵심개념은 위의 그림처럼 이 계층형 파일 시스템에 나타나는 디렉토리 단위로 쪼개서 메타데이터 관리한다는 것입니다. 디렉토리 별로 나눠진 부분들은 독립된 네임노드들이 하나씩 맡아서 관리하게 됩니다.
위의 그림을 예시로 들면, 루트(/) 밑에 Dir1 디렉토리의 밑에 있는 모든 파일과 디렉토리에 대한 메타데이터는 네임노드1이 관리합니다. 같은 논리로 Dir2, Dir3, DIR4 밑에 있는 모든 파일 및 디렉토리도 각각 네임노드 2, 3, 4가 관리합니다.
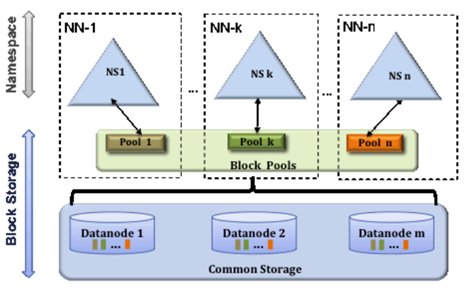
이뿐만 아니라 네임노드는 메모리 상에서 BlockMap을 구성해 블록에 관한 위치정보를 관리하는데 이는 HDFS 페더레이션에서 BlockPool이라는 새로운 형태로서 등장합니다. 블록풀도 역시 디렉토리별로 나눠진 파일 시스템하에서 블록 메타데이터를 보관하고 있습니다.
HDFS 페더레이션에서는 특정 네임노드가 가지는 네임스페이스와 블록풀을 함께 일컬어 네임스페이스 볼륨이라고 부릅니다. 이 네임스페이스 볼룸은 각 네임노드가 독립적으로 관리하기 때문에 하나의 네임노드에 문제가 생긴다고 할지라도 다른 네임노드에 영향을 주지 않습니다.
HDFS 페더레이션에서 데이터노드는 모든 네임노드들의 공용 블록 저장소로 사용됩니다. 동시에 데이터노드는 여전히 Block report와 Heartbeat를 네임노드들에 주기적으로 전송하고 있습니다.
HDFS Federation VS High Availablity
페더레이션과 고가용성은 얼핏 네임노드가 여러개로 수평 확장된다는 점에서 비슷한 개념으로 혼동되기 쉽습니다. 그러나 둘은 전혀 다른 개념입니다.
우선 페더레이션과 고가용성은 네임노드를 수평확장하는 이유가 상이합니다.
페더레이션에서 여러개의 네임노드를 사용하는 이유는 네임스페이스를 수평확장하여 메모리를 효율적으로 관리하기 위해서지만, 고가용성에서 여러개의 네임노드를 사용하는 이유는 네임노드가 단일 장애 지점이라는 약점을 극복하기 위해서 입니다.
이러한 목적성의 차이는 실제 네임노드들의 관계에서 차이를 발생시킵니다.
페더레이션 하에서 각 네임노드는 전혀 관계가 없이 작동합니다. 즉, 페더레이션은 상관관계가 없는 여러개의 네임노드의 집합과도 같습니다. 따라서 페더레이션에서 어떤 네임노드가 장애로인해 다운되더라도 다른 네임노드들에 전혀 영향을 미치지 못합니다.
그러나 고가용성에서는 네임노드들이 서로 관계가 깊습니다. Active 네임노드의 장애를 대비하여 Standby 네임노드가 존재하기 때문이죠.
Standby 네임노드는 평소에 저널노드를 통해 Active네임노드가 작성한 edit log를 읽고 자신의 네임스페이스를 구성합니다. 그리고 Active 네임노드의 장애 발생시, failover과정에서 서로 관련을 맺으면서 Active 네임노드에서 Standby 네임노드로 전환됩니다.
마지막으로 고가용성을 위해서는 별도의 서버에 네임노드를 띄워야하지만, 페더레이션은 그럴 필요가 없습니다.
즉, 페더레이션은 굳이 페더레이션을 위해 별도의 네임노드 서버를 만들지않고 기존의 장비들을 사용해도 된다는 것입니다. 고가용성을 위해서는 반드시 별도로 2개의 네임노드 서버가 구성되야하는 것과는 다르게 말입니다.
현실에서의 HDFS 페더레이션
적어도 국내에서 페더레이션을 적용해서 하둡 클러스터를 구성하고 있는 경우는 없는데, 이는 페더레이션을 구현하기 위해서는 적어도 수천개의 노드로 클러스터를 구성해야하기 때문입니다.
그 정도 규모의 클러스터에서 관리되는 데이터와 그에 대한 메타 데이터가 정도가 아니라면, 평균적으로 사용되는 네임노드 서버의 메모리를 고려할 때, 단일 네임노드로 관리하는데 큰 문제가 없다는 것입니다.
실제로 글로벌 기업중에서도 오래전부터 하둡 클러스터를 대규모로 운영하던 야후 정도가 아닌이상에야 수천개의 노드를 사용해 클러스터를 구성한 사례는 보기 드뭅니다. 게다가 국내 기업들은 대부분 수백개의 노드로 클러스터를 구성하고 있다는 점을 고려하면 페더레이션을 보기 힘든것은 당연합니다.
4. 기타 변경사항
Block Size20
하둡 2.0버전의 HDFS는 기본 블록 사이즈가 이전의 64MB에서 128MB로 변경되었습니다.

클러스터 당 최대 노드수
이전 버전에서는 단일 클러스터당 최대 4000개의 노드로 구성이 가능했습니다. 2.0부터는 단일 클러스터 당 최대 10000개의 노드로 구성이 가능해졌습니다.