하둡은 2.0에 이르러서부터는 빅데이터의 핵심요소로서 완전히 자리잡았습니다. 하둡이 빅데이터 분야의 핵심요소가 되었다는건 그만큼 관련된 경험이 축적되었음을 의미합니다. 이는 모든 상황에서 예외없이 엄청난 자산이죠.
그래서 하둡은 2.0에서 축적된 많은 경험들을 토대로, 3.0에서는 사용자 편의 개선을 위한 다양한 시도를 했습니다. 물론 새로운 개념이 도입된 것이 없지는 않지만, 이전 버전에서 있었던 굵직한 변화들을 보완하고 발전시키는데 많은 초점이 맞춰져 있습니다. 따라서 이번 포스팅은 하둡이 3.0버전을 통해 어떤 문제들을 보완하고 발전시키고자 했는지에 대한 이야기입니다.
1. Erasure Coding(EC) 도입
HDFS의 고질적인 문제 중 하나는 저장해야하는 데이터의 양은 점점 더 많아지는데 복제본을 생성하는 방식은 너무나 많은 스토리지 공간을 요구한다는 점이였습니다. 게다가 물리적인 공간의 한계 때문에 무한정 스토리지를 늘릴 수도 없었기 때문에 저장공간 부족에 허덕이는 기업들까지 등장하기 시작했죠. 이때문에 하둡을 사용하던 많은 기업들은 스토리지 효율성을 개선하기 위한 많은 노력을 기울였습니다.
대표적으로 페이스북이 HDFS와 RAID를 접목시켜 EC를 구현하려는 HDFS-RAID 프로젝트를 런칭했습니다. 페이스북은 자신의 클러스터에 이를 적용해 수십 페타바이트의 저장공간을 확보하는데 성공했지만, RAID의 Recontruction과정에서 버그가 존재해 corrupt block이 생성되는 문제, 그리고 10000개 이상의 파일이 있는 대규모 디렉토리에서 RAID를 구현하는 어려움 등으로 인해 완전한 성공을 이야기 할 수 없었습니다.
그 이후, RIAD 구성없이도 EC를 HDFS와 직접 결합시켜 동일한 수준의 fault tolerance를 가지면서도 더 적은 스토리지 사용량을 가질 수 있다는 가능성을 발견한 클라우데라와 인텔의 엔지니어들은 HDFS-EC 프로젝트를 런칭했습니다. 그리고 그 결실을 맺어 결국 하둡 3.0부터 공식적으로 도입되기에 이르렀습니다.
HDFS Replication (3.0 이전)
EC에 대해 본격적으로 이야기하기 전에 우선 HDFS의 Replication에 대해 간략하게 이야기할 필요가 있습니다. 이 포스팅의 핵심은 결국 EC와 Replication이라는 두 저장방식에 대한 비교이기 때문입니다.
HDFS의 Replication에는 블록 크기와 Replication Factor(RF, 복제계수)라는 두 핵심개념이 있습니다. 블록크기는 블록 하나당 가질 수 있는 최대의 크기를 의미하고 복제 계수는 시스템 내 몇개의 복제본을 가질 것인가에 관한 것 입니다.
HDFS에 들어온 데이터는 우선 여러개의 블록으로 나누어집니다. 그리고 블록수는 할당된 블록 크기가 얼마냐에 따라 달라집니다. 블록이 생성되면 HDFS 클러스터 전체에 복제가 됩니다. 기본 설정을건들지 않았다면 복제본의 수는 3개(원본 1 + 복제본 2)입니다. 이 복제본을 생성함으로서 HDFS는 데이터의 중복성을 얻게 됩니다. 이 중복성은 이후 블록의 유실이 발생했을 때 복원을 가능케하며 HDFS가 fault tolerance를 갖게 합니다.
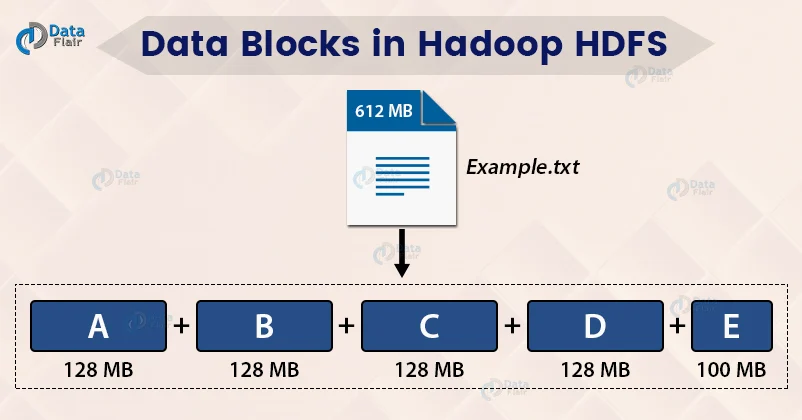
위의 그림에서 612MB의 텍스트 파일은 128MB 블록 4개와 100MB블록 1개로 나누어집니다. 복제계수가 기본설정을 따른다면, 5*3 = 15 개의 블록이 만들어집니다. 그리고 이를 저장하기 위해서 612 * 3 = 1836MB의 스토리지가 필요합니다.
즉, 복제계수 3을 따르는 HDFS에서 데이터를 저장하면 원본 데이터의 3배에 달하는 스토리지가 필요합니다. 이는 주어진 스토리지 용량의 1/3밖에 사용하지 못하는 비효율성을 갖는다는 것이고 200%의 스토리지 오버헤드가 발생한다는 것입니다. 물론 추가 복제본의 수인 2개만큼 fault tolerance를 갖는다는 장점이 있지만, Replication으로 인해 하둡 클러스터의 스토리지 활용도가 얼마나 제한받는지도 알 수 있습니다. 심지어 이를 페타 바이트 단위로 확장한다면 스토리지 효율성 문제는 더욱 크게 다가 오겠죠.
Erasure Coding(EC)
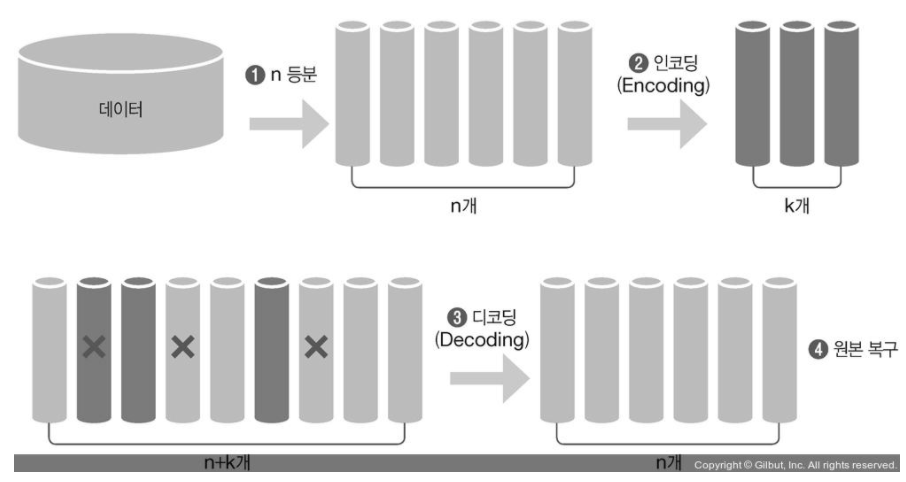
Erasure Coding은 데이터 보호를 위해 고안된 데이터 저장 방식의 일종입니다. 주로 RAID로 스토리지 시스템을 구성할 때 사용되었습니다.
EC는 셀 이라고하는 균일한 크기의 데이터 단위에서 작동합니다. EC는 이 N개의 셀을 인자로 받아 K개의 패리티 셀을 생성하는데 이 과정을 인코딩(Encoding)이라고 합니다.
이후 셀이 유실되거나 손상 될 때는 남은 셀과 패리티 셀을 가지고 원본을 복구해냅니다. 이과정을 디코딩(Decoding)이라고 합니다.
EC의 중요한 파라메터는 EC 코덱과 N, K의 값입니다.
코덱은 어떤 알고리즘을 사용해서 인코딩과 디코딩을 할건지에 관한 것입니다. 다시말하면 어떤 알고리즘을 사용해서 패리티 셀을 만들고 이를 통해 유실된 데이터를 복구할 건지를 결정합니다.
N,K는 인코딩 과정에서 코덱이 몇개의 셀을 인자로 받아서 몇개의 패리티셀을 만들어 낼 건인지에 관한 것입니다. 이때 인자로 받는 데이터 셀의 개수가 N이고 아웃풋으로 생성되는 패리티 셀의 개수가 K입니다. 이렇게 생성된 데이터 셀과 패리티 셀을 합쳐서 인코딩 그룹이라고도 합니다.
EC 코덱(알고리즘)
EC는 어떤 코덱을 사용하느냐와 N,K의 값을 몇으로 하느냐에 따라 다양한 양상이 나타납니다.
우선 코덱으로 사용가능한 알고리즘은 Reed Solomon(이하 RS)과 XOR이 있습니다. 그런데 XOR 방식은 손실이 허용되는 최대의 셀의 개수가 1개이기 때문에 Fault tolerance에 제한이 있어 다수의 실패를 허용해야하는 HDFS와 같은 시스템에서는 충분하지 않습니다. 그래서 적어도 HDFS에서는 XOR방식은 거의 사용되지않고 대부분 RS를 사용하여 EC를 구현합니다. 반면 RS는 정교한 선형 대수 연산을 사용해서 여러 패리티 셀을 생성하기 때문에 복수의 셀의 손실을 허용할 수 있습니다.
또한 RS를 사용하면 N과 K에 대해 서로 다른 값을 선택하여 data durability(=Fault tolerance)과 스토리지 효율성을 유연하게 조정할 수 있습니다. 여기서 패리티 셀의 수를 의미하는 K는 허용할 수 있는 스토리지의 오류 수 즉, Fault tolerance를 결정합니다.
스토리지 효율성은 패리티 셀에 대한 데이터 셀의 비율인 N/(N+K)라는 식으로 계산할 수 있습니다. 아래의 표는 replication, XOR 및 RS의 fault tolerance와 스토리지 효율성 비교한 내용입니다.
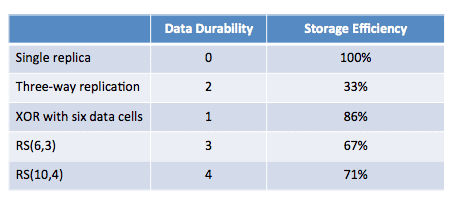
여기서 주목해야할 건 Three-way replication과 RS(N, K)입니다.
Three-way replication은 HDFS의 기본 값인 RF가 3인 경우를 보여줍니다. HDFS의 기본 설정을 따를 경우 Fault tolerance는 2이고 스토리지 효율성은 33%에 불과합니다. 반면 두 RS방식을 사용하면 모든 요소에서 HDFS의 기본설정보다 절대 우위를 갖게 됩니다.
Block layout
분산 스토리지 시스템에서는 매우 큰 파일을 관리하기 위해 일반적으로 Logical block이라고 하는 고정된 크기의 논리 바이트 범위로 나눕니다. 그런 다음 이러한 logical block은 클러스터의 storage block에 매핑 되며, 이는 클러스터에 있는 데이터의 물리적인 레이아웃을 반영합니다.
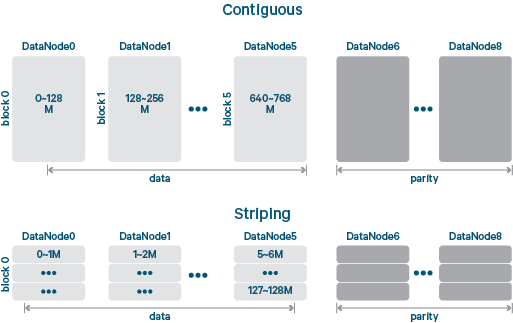
logical block과 storage block 간의 가장 간단한 매핑방식은 각 logical block을 일대일로 storage block에 매핑하는 contiguous block layout입니다. contiguous layout으로 파일을 읽을 때는 각 storage block을 순서대로 읽는 것 만큼 간단합니다.
반면, striped block layout은 logical block을 셀이라고 하는 훨씬 더 작은 storage unit으로 나누고 storage block 그룹에 라운드 로빈 방식으로 셀 스트라이프를 작성합니다. striped layout에 있는 파일을 읽으려면 logical block의 storage block 그룹을 쿼리한 다음 storage block 그룹에서 셀의 스트라이프를 읽어야합니다.
block layout 차원에서 스트라이핑은 병럴처리가 가능하기 때문에 conitnguous block layout보다 더 나은 I/O처리량을 제공할 수 있습니다.
실제로 HDFS-EC프로젝트에서 가장 중요한 결정 중 하나는 어떤 block layout을 사용할 것인지 결정하는 것이였습니다. contiguous block layout은 기존의 HDFS 시스템과 매우 유사하기 때문에 구현하기는 더 쉽습니다. 다만 전체 스트라이프를 작성할 때만 스토리지 효율성을 가질 수 있기 때문에 파일이 상당히 큰 경우에만 적합하다는 한계가 있습니다.
가령 RS(10,4)를 사용한다고 할 때, 128MB의 데이터를 저장해야하는 경우 블록은 1개지만 패리티 블록은 4개를 만들어야 합니다. 즉, 400% 스토리지 오버헤드가 발생하여 기존 Replication 보다 더 나쁜 스토리지 효율성을 갖게 됩니다.
반면, Striped block layout의 경우 셀 크기가 훨씬 작기 때문에 작은 파일과 큰 파일 모두에서 스토리지 절약을 실현할 수 있습니다.
결국 어떤 block layout을 선택하느냐는 파일의 크기가 가장 중요합니다. 만약 클러스터의 스토리지 사용량이 큰 용량의 데이터에 의해 대부분 사용된다면, 여러개의 작은 파일의 블록을 단일 그룹으로 결합하는 구현문제를 피할 수 있기 때문에 contiguous block layout이 적합합니다. 그러나 클러스터 용량이 작은 파일에 의해 대부분 사용된다면, striped block layout이 스토리지 효율성 측면에서 더 적합한 선택이 됩니다.
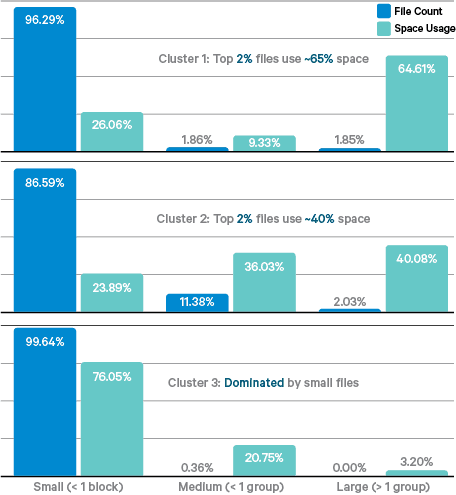
클라우데라의 실증적인 연구에 따르면 HDFS에서 작은 파일들의 클러스터 스토리지 사용량이 적게는 36%에서 많게는 97%까지 차지합니다. 그래서 클라우데라의 엔지니어들은 작은 파일을 처리하는 것이 매우 중요하다고 판단하여 HDFS-EC의 첫 단계로 stiped block layout으로 EC를 지원하도록 했습니다.
(참고로 현시점에서 contiguous block layout의 지원을 위해 여러 프로젝트들이 진행되고 있습니다.)
HDFS에서의 EC
EC 정책
EC 정책은 알고리즘, N,K의 값 그리고 셀 사이즈의 크기를 합쳐서 표기합니다. 다만 셀 사이즈는 디폴트로 1024k이기 때문에 RS(3,2), RS(6,3)같이 간단히 표기하기도 합니다. 5가지 기본 정책은 아래와 같습니다.
<EC 정책>
- RS-3-2-1024k
- RS-6-3-1024k (기본값)
- RS-10-4-1024k
- RS-LEGACY-6-3-1024k
- XOR-2-1-1024k
4개의 RS 정책과 하나의 XOR 정책이 기본적으로 제공되고 있고 처음 시작하면 RS-6-3-1024k만 Enable 상태로 되어있습니다. 기본 정책 중 다른 것이 필요하다면, Enable 시켜서 사용할 수 있고, 자신이 커스텀하여 새로운 정책을 만들어 사용할 수도 있습니다.
작동 원리
(이 파트는 다분히 개인적인 이해를 바탕으로 작성했기 때문에 전적으로 이 내용을 믿는다기보단, 교차검증을 통해 확인하시길 권장드립니다.)
기존 HDFS는 logical block과 storage block의 구분이 의미가 없었기 때문에 HDFS-EC프로젝트의 주요 목표 중 하나는 스트라이핑을 지원하기 위해 블록의 개념을 일반화 하는 데 있었습니다. 즉, contiguous block layout의 가정은 HDFS의 내부 논리에 아주 광범위하고 깊숙히 포함되어 있었기 때문에 striped block layout을 지원하기 위해서는 logical block과 storage block의 개념을 구분할 필요가 있었다는 것입니다.
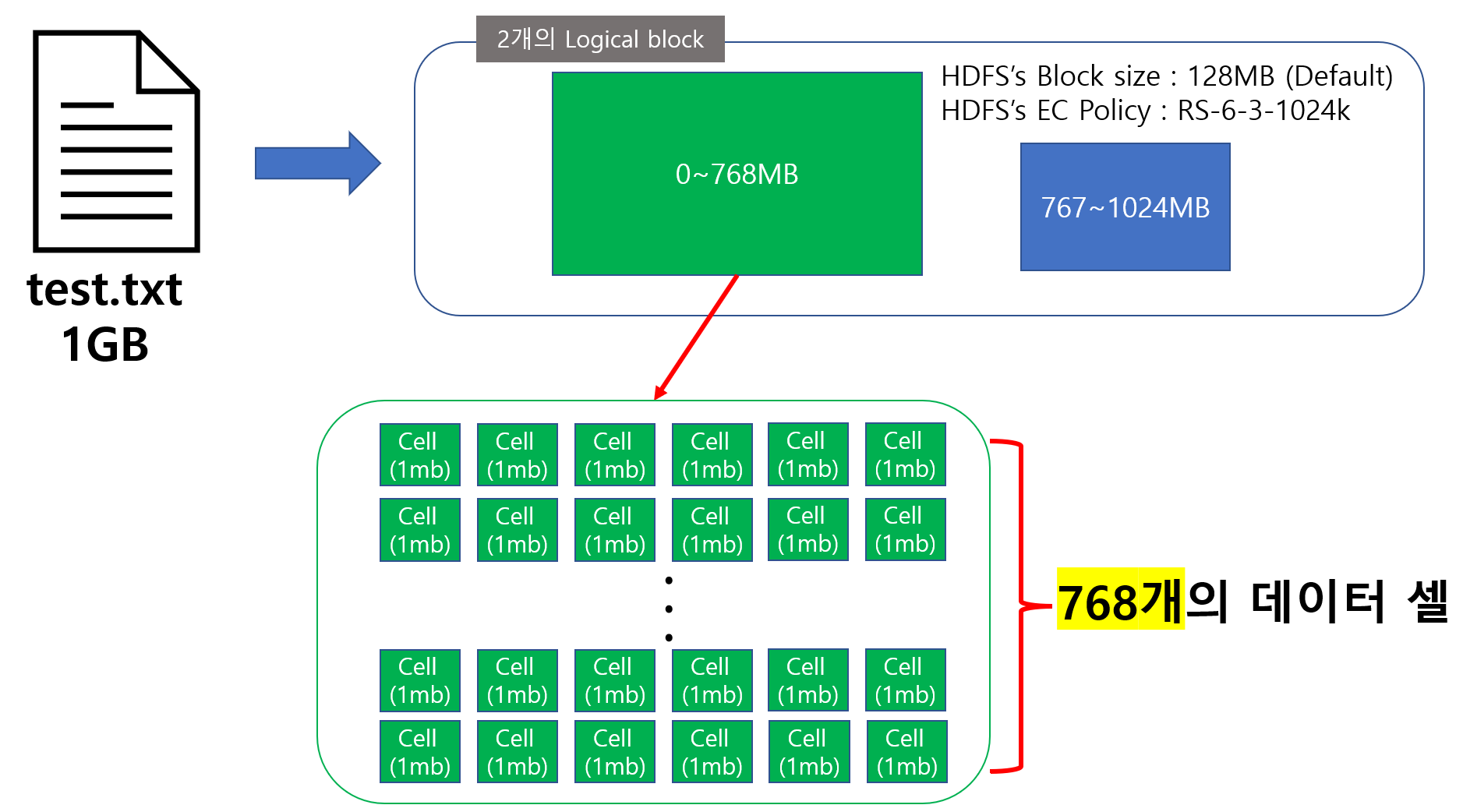
logical block은 파일의 논리적인 바이트 범위를 나타내고 storage block은 데이터 노드에 실제 저장되는 데이터 블록입니다. 이를 좀더 명확하게 이해하기위해 RS-6-3-1024k의 EC정책으로 1GB의 데이터를 저장하는 경우의 동작을 한번 살펴보겠습니다.
striped block layout에서 기억해야할 가장 큰 특징은 스트라이핑된 셀들을 가지고 블록을 구성한다는 사실입니다. RS-6-3-1024k 정책을 따른다는 것은 데이터를 스트라이핑 하여 1MB의 데이터 셀로 나누고 이를 가지고 6개의 블록과 3개의 패리티 블록을 만든다는 의미입니다.
따라서 1GB의 파일이 HDFS에 들어오면 우선 1024개의 셀로 스트라이핑됩니다. 그러나 1024개의 데이터 셀로 6개의 데이터 블록을 만들지 않습니다. 실제로 데이터 노드에 저장되는 블록은 Storage block 인데, 이는 HDFS의 Block size를 상속받아 최대 128mb의 크기를 갖기 때문입니다. 결국 Storage block을 기준으로 생성하면 8개의 블록이 생성되어야하기 때문에 EC는 이 문제를 시스템적으로 극복하기 위해 logical block을 사용하여 파일의 논리 바이트 범위를 설정하여 파일을 구분 짓고 별도의 그룹으로 만들어 스트라이핑합니다.
다시 예시로 돌아가 보면, EC는 1GB의 파일 중 1MB~768MB까지의 셀을 하나의 logical block으로 묶고 769~1024MB의 셀은 또다른 logical block으로 묶어 구분 짓습니다. 여기서 logical block의 구분 원리는 단순히 storage block 6개가 가지는 최대 크기인 128*6=768MB을 기준으로 나누는 것 입니다. 이 기준은 EC정책의 블록 갯수에 따라 달라지기 때문에 같은 예시에서 RS-10-4-1024k면 하나의 logical block이 만들어 지고 RS-3-2-1024k면 3개의 logical block이 만들어 질 겁니다.
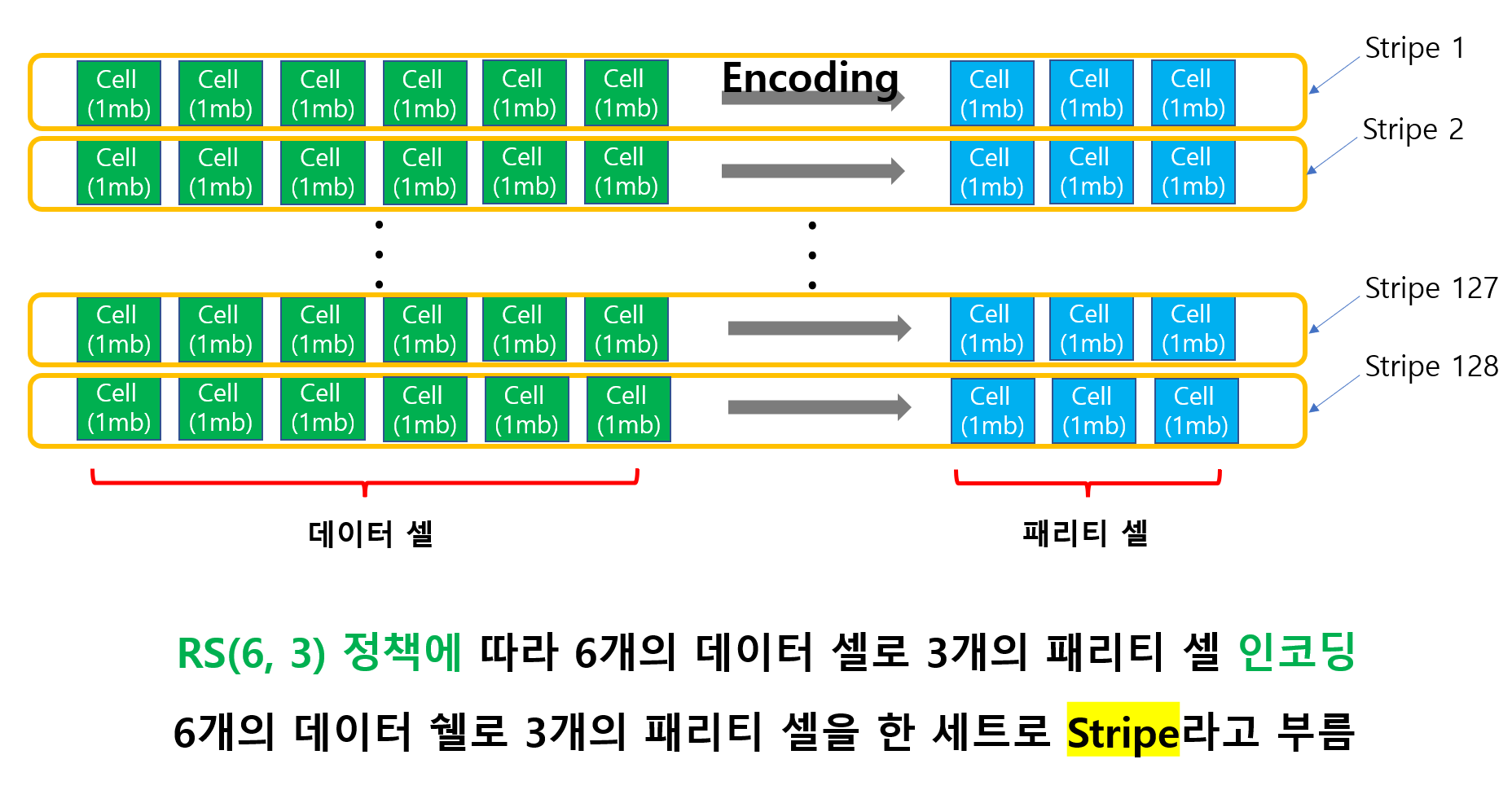
첫번째 logical block은 768개의 데이터 셀을 가지고 있습니다. 이 셀들은 Storage block에 저장하기 전에 EC 정책에 따라 인코딩이 이루어집니다. 6개의 데이터 셀은 하나로 묶여서 3개의 패리티 셀을 생성하고 이 데이터 셀 6개와 패리티 셀 3개는 스트라이프(Stripe)라는 단위로 묶입니다.
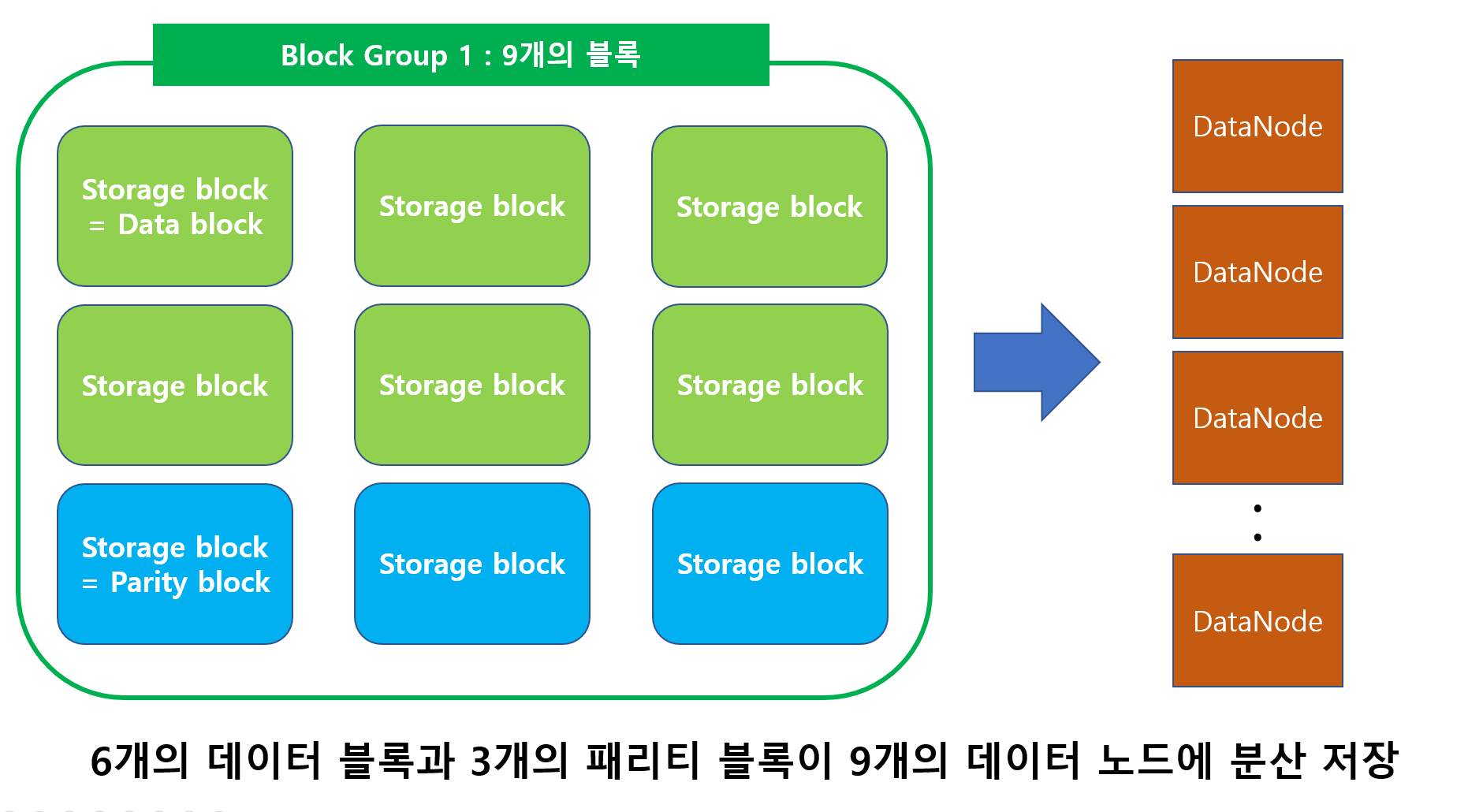
인코딩 작업의 결과 768개의 데이터 셀과 384개의 패리티 셀이 만들어집니다. 이제 데이터 셀은 6개의 Storage block에 나누어 저장되고 패리티 셀은 3개의 Storage block에 저장됩니다. 데이터 셀이 저장된 6개의 Storage block은 이제 데이터 블록이고 패리티 셀이 저장된 3개의 Storage block은 패리티 블록이 됩니다. 이 6개의 데이터 블록과 3개의 패리티 블록은 이제 하나의 block group으로 묶이고 각 블록들은 9개의 데이터 노드에 분산되어 저장됩니다.
이때 Storage block들은 인덱스를 부여받아 logical block에 매핑됩니다. 이는 네임노드가 데이터노드의 block report를 처리할 때 필요합니다.
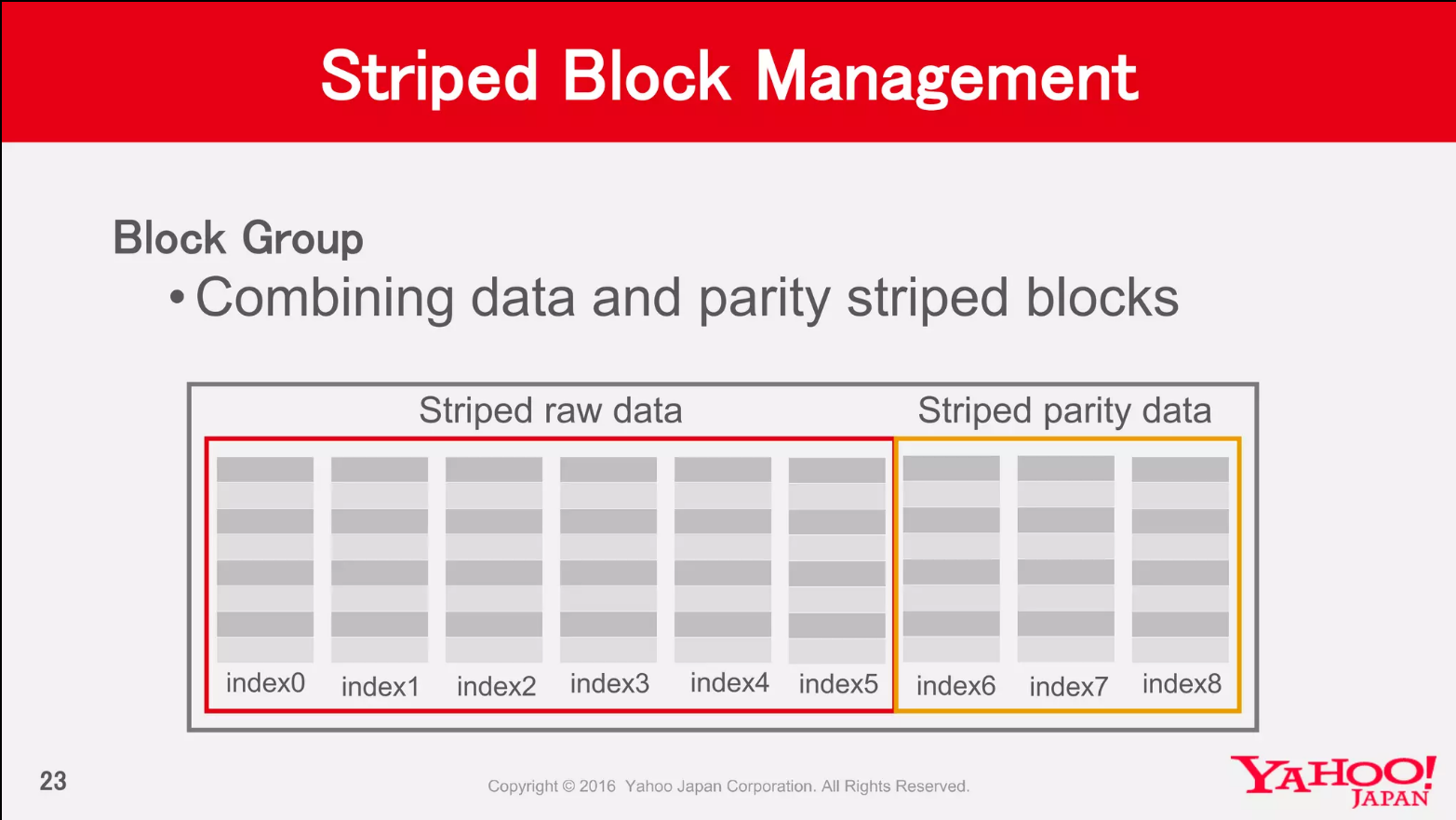
두번째 logical block도 같은 메커니즘입니다. 똑같이 6개의 데이터 블록과 3개의 패리티 블록이 만들어지고 또 하나의 block group으로 묶이고 각 블록들은 9개의 데이터 노드에 분산되어 저장됩니다. 참고로 block group의 storage blcok은 internal block이라고 불리기도 합니다.
결국 1GB의 데이터를 RS-6-3-1024k 정책에 따라 HDFS에 저장하니 18개의 블록이 만들어졌고 약 1.5GB의 용량이 저장됩니다. Replication 방식을 사용했을 때 24개의 블록이 만들어지고 3GB의 용량이 저장된다는 것과 비교해보면 50%의 저장 공간 절약에 성공한 것입니다.
HDFS 아키텍쳐 변화
HDFS는 이러한 EC의 작동을 지원하기 위해 기존 아키텍쳐들에 변화를 주었습니다.
네임노드 확장
블록이 logical block과 storage block으로 구분됨에 따라서 이전과 같은 방식으로 블록 ID를 지정하게되면, 네임노드는 blockMap에서 logical block과 storage block을 구분해서 관리해야 했습니다. 그래서 striped layout으로 저장한 파일을 읽으려면 logical block을 찾고 logical block의 storage block 그룹을 쿼리한 다음 storage block 그룹에서 셀의 스트라이프를 읽어야합니다.
결국 이처럼 네임노드가 블록 ID를 이전보다 더 많이 관리했어야 했었기 때문에 이로 인해 네임노드의 blockMap의 크기가 250~440%까지 비대해지는 문제점이 있었습니다. 그래서 하둡은 3.0버전에 EC를 도입하면서 네임노드의 블록 메타데이터를 관리하기 위해 계층적 블록 명명 프로토콜(hierarchical block naming protocol)을 도입했습니다.
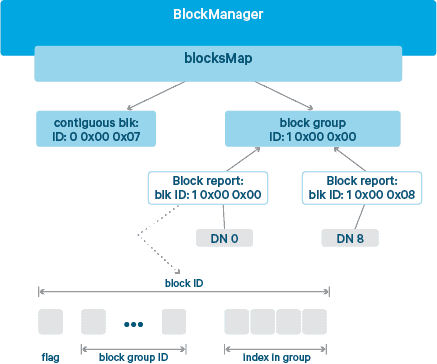
기존 HDFS는 블록 생성 시간을 기준으로 블록 ID를 순차적으로 할당하지만, 이 프로토콜은 각 블록 ID를 2~3의 섹션으로 나눕니다. Contiguous layout인 경우 2개이고 Striped layout인 경우 3개의 섹션을 갖습니다.

각 블록 ID는 Block layout을 나타내는 Flag로 시작합니다. 이는 Contiguous layout이면 0 Striped layout이면 1의 값을 갖습니다. Striped layout인 경우, 블록 ID는 뒤이어 두 섹션이 구성되는데 하나는 logical block의 ID를 표시하는 중간 섹션과 logical block의 Storage block의 인덱스를 나타내는 꼬리 섹션입니다. 이를 통해 네임노드는 logical block을 Storage block의 요약본으로 관리할 수 있습니다. 실제로 클라우데라의 실증적인 실험 결과에 따르면, 이 프로토콜을 사용하면 네임노드의 blockMap을 21~71%만 증가시킵니다.
클라이언트 확장
데이터 스트라이프 및 EC를 수용하기 위해 DFSInputStream(Java 데이터 형식)을 DFSStriped InputStream으로 확장하고 DFSOutputStream(Java 데이터 형식)을 DFSStriped OutputStream으로 확장합니다. 이제 논리 블록과 저장 블록이 분리되어 있으므로 striped 데이터 유형을 사용하여 HDFS에서 블록의 병렬 생성/처리를 활성화할 수 있습니다.
데이터노드 확장
클라이언트 측에서 비용이 많이 드는 포그라운드 데이터 재구성(Reconstruction)의 가능성을 피하기 위해서는 백그라운드에서 데이터 노드의 장애를 식별하고 해결하는 것이 중요합니다. Replication과 마찬가지로 네임노드는 EC 스트라이프에서 누락된 블록을 추적하고 복구 작업을 데이터노드에 할당합니다. 이때 데이터 노드의 복구 작업은 누락된 EC 블록을 재구성하기 위해 ECW(EraseCodingWorker)라는 새로운 구성 요소에 의해 처리됩니다.
먼저 오류가 발생하지 않은 모든 데이터 원본에 대한 읽기 요청을 보냅니다. 응답을 받으면 ECW는 ISA-L이라는 인텔의 RS EC 코덱 프레임워크를 사용하여 데이터를 디코딩하고 복구된 데이터를 실패한 데이터노드에 전송합니다. 더 구체적인 메커니즘은 아래와 같습니다.
소스 노드에서 데이터 읽기: EraseCodingWorker 시작 시간에 초기화된 전용 스레드 풀은 서로 다른 원본 노드에서 데이터 블록을 읽는 데 사용됩니다. EC 스키마를 기반으로 모든 소스 대상에 대한 읽기 요청을 예약하고 재구성에 필요한 최소 입력 블록만 읽도록 합니다.
데이터 디코딩 및 출력 데이터 생성: ECWorker는 EC 클라이언트와 마찬가지로 Erase Codec Framework에 도입될 코덱 프레임워크를 사용하여 디코딩/인코딩 작업을 완료합니다.
생성된 데이터 블록을 대상 노드로 전송합니다. 디코딩이 완료되면 출력 데이터를 패킷으로 캡슐화하고 대상 데이터 노드로 전송합니다.
언제나 EC는 좋은가?
블록의 개수 측면
스토리지 효율성 측면에서는 Replication보다 EC가 좋습니다. 그러나 문제는 아주작은 파일데이터를 다룰 때 일어납니다.
Replication은 아주 작은 파일의 경우에도 하나의 블록과 복제본 2개를 생성하면 됩니다. 그러나 EC는 정책에 따라 아주 작은 파일도 여러개의 블록과 패리티 블록으로 나누어 저장합니다.
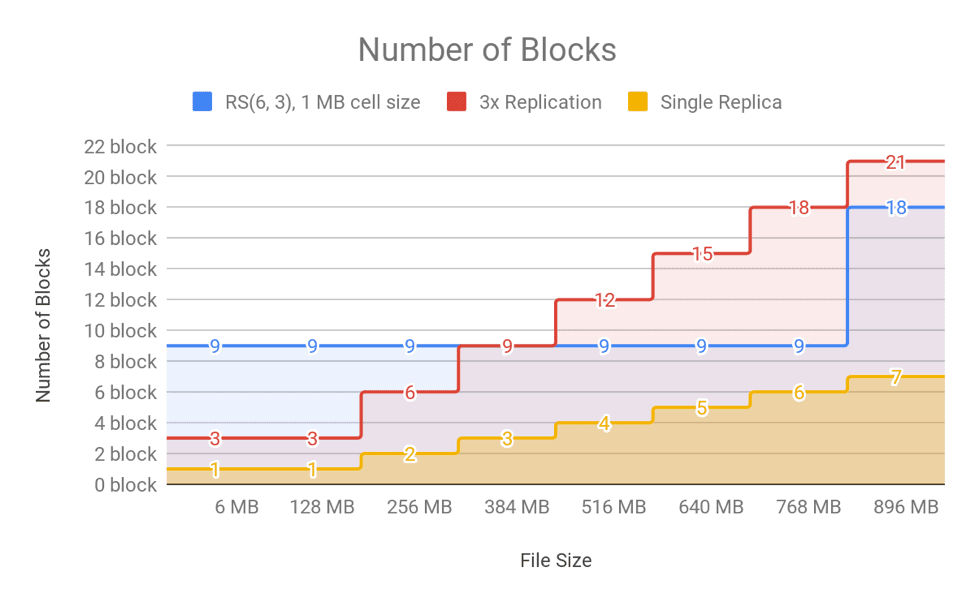
위의 그림은 파일의 크기에 따른 블록의 수를 보여주는 자료입니다. 128MB 이하의 데이터를 저장하는 경우를 보면, Replication은 블록 단 3개만 생성합니다. 하지만 RS-6-3-1024k로 저장하면 반드시 6개의 블록과 3개의 패리티 블록을 생성해야하기 때문에 총 9개의 블록이 만들어집니다. 물론 Replication은 1283=384MB의 저장공간을 필요로 하지만, Replication은 1281.5=192MB의 저장공간만 필요합니다.
그러나 블록의 개수가 많아진다는 것은 블록의 메타데이터가 많아진다는 것을 의미합니다. 그리고 블록 메타데이터가 많아진 다는 건 네임노드에 부하가 걸릴 가능성이 높아진다는 것을 의미합니다.
특히나 클라우데라의 경험적인 결과에 따르면 하둡 클러스터의 스토리지는 적게는 36%에서 많게는 97%까지 작은 파일에 의해서 사용됩니다. 만약 이 작고 많은 데이터를 모두 EC로 관리하게 된다면 네임노드의 오버헤드는 필연적일 수 밖에 없습니다. 위의 그림에서 보면 RS-6-3-1024k일때는 저장되는 파일의 크기가 적어도 385MB이상 이여야지만 EC가 효과적이라고 볼 수 있습니다.
그래서 실제로 EC를 사용하는 기업들은 자주 사용되지않는 큰 용량의 Cold 데이터를 관리하는데에 한정하고 있습니다. 대표적으로 Line Coporation이 Cold 데이터에 대해서 EC로 관리하여 12PB의 저장공간을 절약하는데 성공한 사례가 있습니다.
CPU 사용량 측면
앞선 이야기들에서 보듯이 EC에서의 인코딩/디코딩은 단순 복제방식에 비해서 상당히 복잡한 메커니즘을 가지고 있습니다. 이로인해 상당히 많은 CPU 사용량이 발생하고 결국 오버헤드가 발생할 수 있습니다.
다행히도 하둡은 인텔의 ISA-L이라는 오픈 소스 지능형 스토리지 가속 라이브러리를 통해 충분한 개선이 가능하도록 지원합니다. 이때문에 EC에서의 RS 알고리즘을 ISA-L을 기반으로하는 알고리즘과 순수 자바라는 두가지 형태로 구현했습니다.
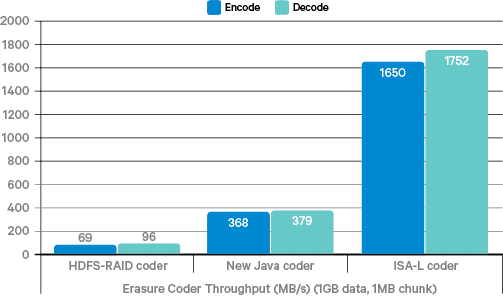
위 그림은 메모리 내 인코딩/디코딩 벤치마크의 결과입니다. ISA-L은 순수 자바 코더보다 4배 이상의 성능을 보이고 페이스북의 HDFS-RAID 코더와 비교해보면 20배 이상의 차이가 납니다.
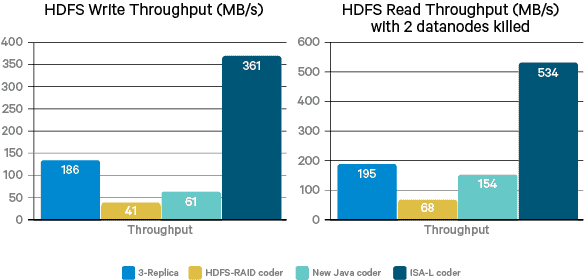
또한 위의 그림은 다양한 코더들을 사용하여 HDFS I/O 성능을 비교한 내용입니다. 순수 자바 코더는 쓰기와 읽기 모두에서 상당히 제한된 수준의 처리량만을 보입니다. 그러나 ISA-L 코더를 사용하면, 뛰어난 CPU 효율성으로 인해 순수 자바 코더보다 압도적으로 빠른 성능을 보입니다. 또한 striped layout으로 인해 클라이언트가 여러 데이터노드와 병렬로 I/O를 수행하여 디스크 드라이브의 모든 대역폭을 활용할 수 있기에 복제 방식보다 성능이 2~3배 향상됩니다.
이러한 압도적인 성능의 향상때문에 HDFS-EC는 ISA-L의 사용을 강력히 권장하고 있습니다. 디폴트는 순수 자바 코더지만, 라이브러리 설치를 통해 ISA-L을 사용하도록 할 수 있습니다.
결론
결론을 요약하자면, EC는 동일한 수준의 fault tolerance를 유지하면서 replication에 비해 HDFS의 스토리지 오버헤드를 약 50% 줄일 수 있습니다. 그 결과 사용자가 동일한 규모의 스토리지에 두 배의 데이터를 저장할 수 있으므로 하드웨어 지출이 크게 절감됩니다.
또한, 새로운 계층적 블록 명명 프로토콜을 사용하여 네임노드에 대한 추가 오버헤드를 최소화하고 패리티 정보의 고성능 인코딩/디코딩을 위해 인텔의 ISA-L을 활용합니다.
2. 다수의 Standby 네임노드
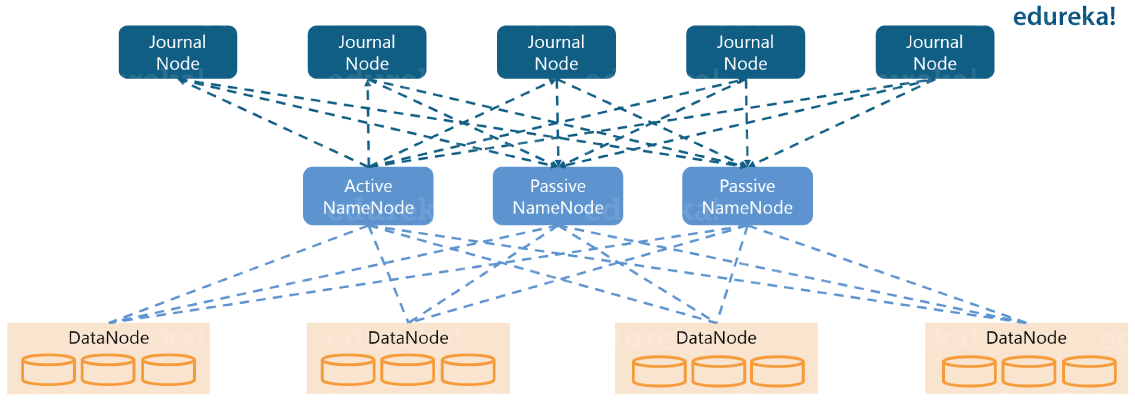
하둡 2.0에서 HA는 하나의 Active 네임노드와 하나의 Standby 네임노드로 구현합니다. 이 HA 아키텍쳐에서는 단 하나의 네임노드의 장애만을 허용합니다.
그러나 두 개의 네임노드를 가진 HA 구성은 사용자들을 충분히 안심시켜줄 수 없었습니다. 하둡이 본격적으로 빅데이터 분야에 핵심으로 자리잡게 되면서 단순히 내부 데이터 분석이 아닌 서비스를 위한 인프라에도 본격적으로 사용됐기 때문입니다. 사용자들은 안정적인 서비스를 위해 더 높은 수준의 fault tolerance를 요구하기 시작했고, 다시 한번 네임노드의 Fault tolerance가 치명적인 약점이 되어버린 것이죠.
그래서 하둡은 3.0부터 한개의 Active 네임노드와 다수의 Standby 네임노드로 HDFS HA를 구성할 수 있습니다. 위의 그림은 한 개의 Active 네임노드와 두 개의 Standby 네임노드, 그리고 다섯 개의 저널노드로 구성된 HDFS HA아키텍쳐로 2개의 네임노드에 대한 Fault tolerance를 가지고 있습니다.
3. Intra-DataNode Balancer
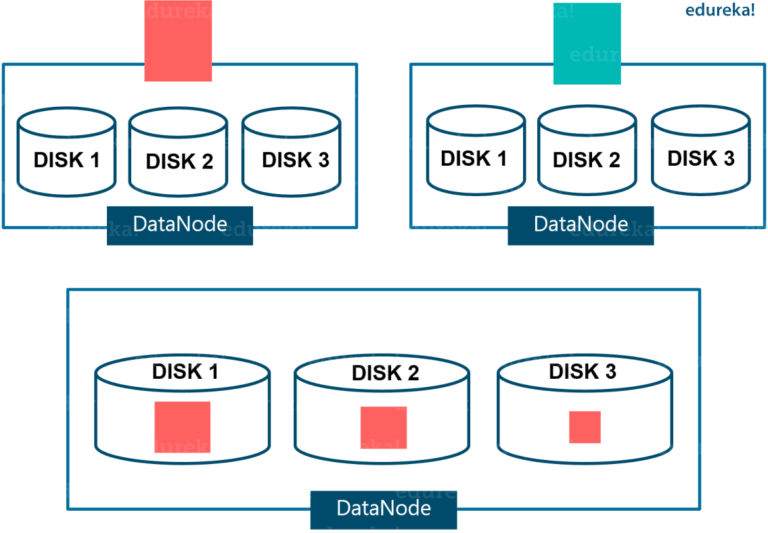
데이터 노드에 대해서 기억해야할 부분은 데이터 노드는 실제 사용에 있어서 여러개의 디스크로 구성되며 데이터 노드는 이 디스크들을 관리한다는 사실입니다. 정상적인 상황에서 쓰기작업이 발생하면 데이터가 균등하게 분할되기 때문에 디스크의 밸런스에는 문제가 발생하지 않습니다.
그러나 디스크를 추가하거나 교체할 때는 데이터 노드 내의 디스크 밸런스가 왜곡되는 현상이 발생합니다. 이 상황은 이전 2.0에서의 HDFS Balancer로는 컨트롤 할 수 없었습니다.
그러나 하둡 3.0부터는 CLI에서 hdfs diskbalancer 명령어를 호출하는 것으로 해결이 가능해졌습니다.
4. 기타 변화들
Observer 네임노드
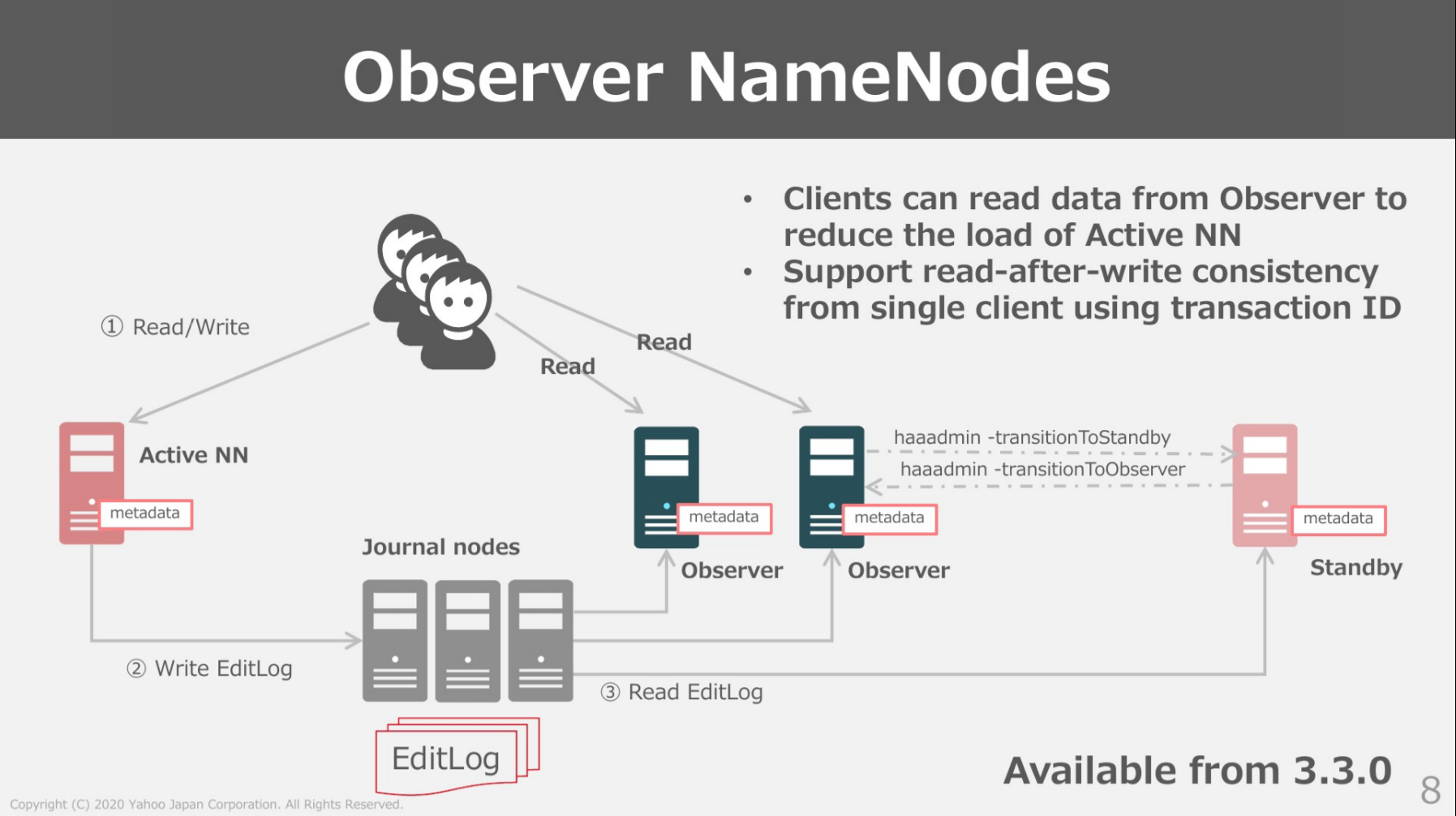
HDFS HA에서는 Active 네임노드는 모든 클라이언트 요청을 처리하는 역할을 하는 반면, Standby 네임노드는 저널 노드의 edit log를 읽어 네임스페이스에 대한 최신 정보를 유지하고 모든 데이터 노드에서 block report를 수신하여 blockMap을 구성합니다.
이 아키텍처의 단점 중 하나는 하둡 클러스터를 운영하면서 블록 메타데이터가 많아지면 Active 네임노드가 단일 병목 지점이 될 수 있다는 것에 있습니다. 특히 사용량이 많은 클러스터에서 클라이언트 요청으로 과부화될 수 있다는 것입니다. 하둡은 이러한 문제를 해결하기 위해 Observer 네임노드를 3.0버전부터 새로이 도입했습니다.
Observer 네임노드도 Standby 네임노드와 마찬가지로 네임스페이스와 blockMap를 최신상태로 유지합니다. 그리고 Active 네임노드와 같은 일관된 읽기를 제공하는 기능도 있습니다. 일반적인 상황에서 클라이언트의 요청 중 대다수는 읽기 작업이기 때문에 observer 네임노드가 클라이언트의 읽기 요청을 분산처리 해주어 Active 네임노드의 부담을 크게 덜어줄 수 있습니다.
결과적으로 oberser 네임노드를 도입하면, Active 네임노드에 가해지는 트래픽의 부하를 분산시켜 병목 지점이 되는 것을 막고, 나아가 하둡 클러스터의 전체 처리량/처리속도를 개선하는 데도 도움을 줄 수 있습니다. 다만 Observer 네임노드로 HA를 구성하고자 하는 경우에 네임노드들간 상태 전환에 제한이 있다는 점을 기억해야합니다. Standby 네임노드는 Observer 네임노드로 전환이 가능하지만, Active 네임노드는 Observer 네임노드로 전환이 불가능하기 때문입니다. Active 네임노드를 observer 네임노드로 전환하고 싶다면 Standby로 전환한 후 observer 네임노드로 전환해야 가능합니다.
HDFS 라우터 기반 페더레이션(Router-based Federation)
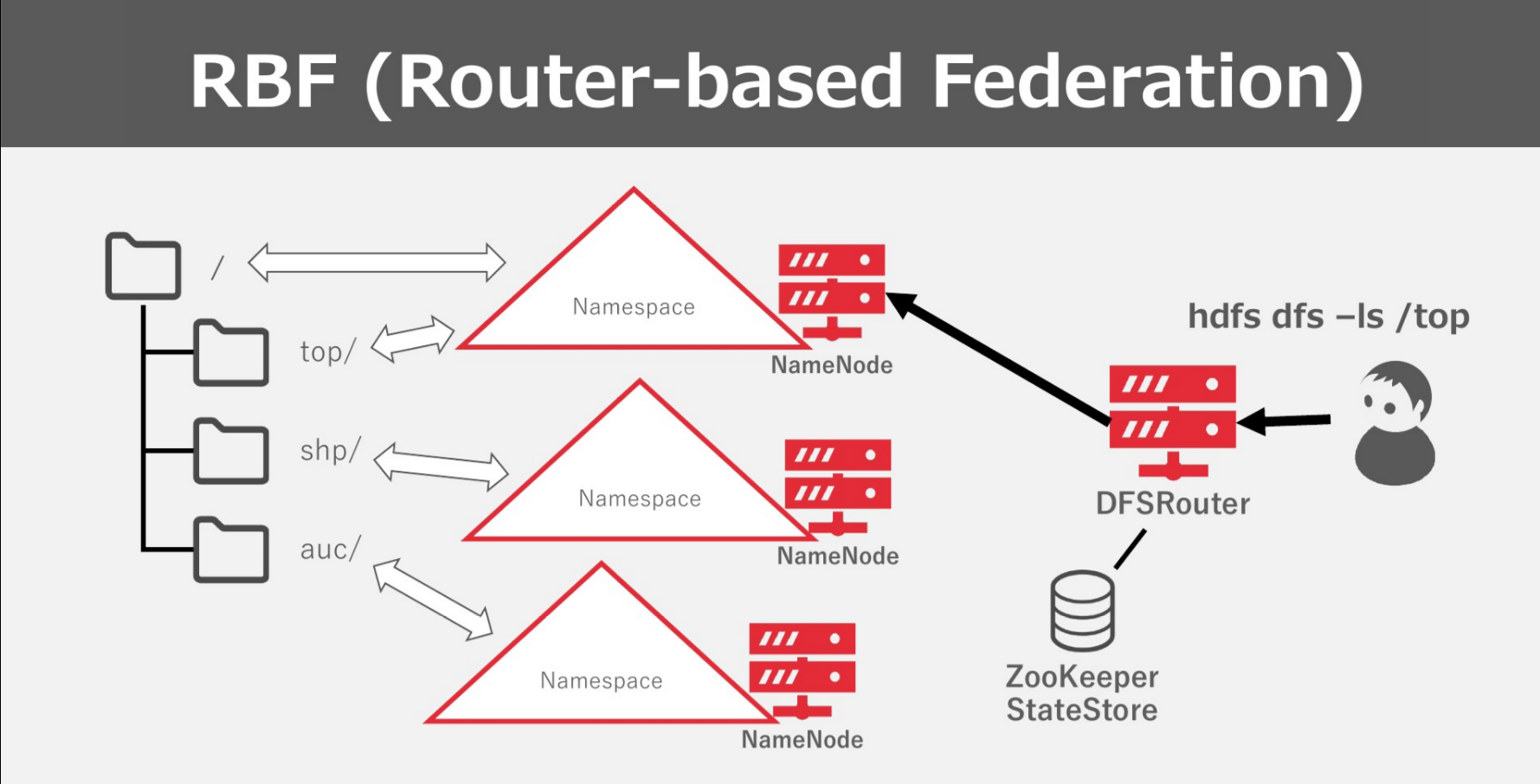
이전 버전의 HDFS 페더레이션은 논리적으로 네임 노드와 네임스페이스를 추가하고 데이터 노드를 공유하게 하여 subcluster를 추가하는 것과 같은 아키텍쳐를 가졌습니다. 하둡 3.0(정확하게는 2.9 버전에 처음 등장)에서는 HDFS 라우터라는 역할을 추가하여 물리적인 클러스터 간에 페더레이션이 가능하도록 지원합니다.
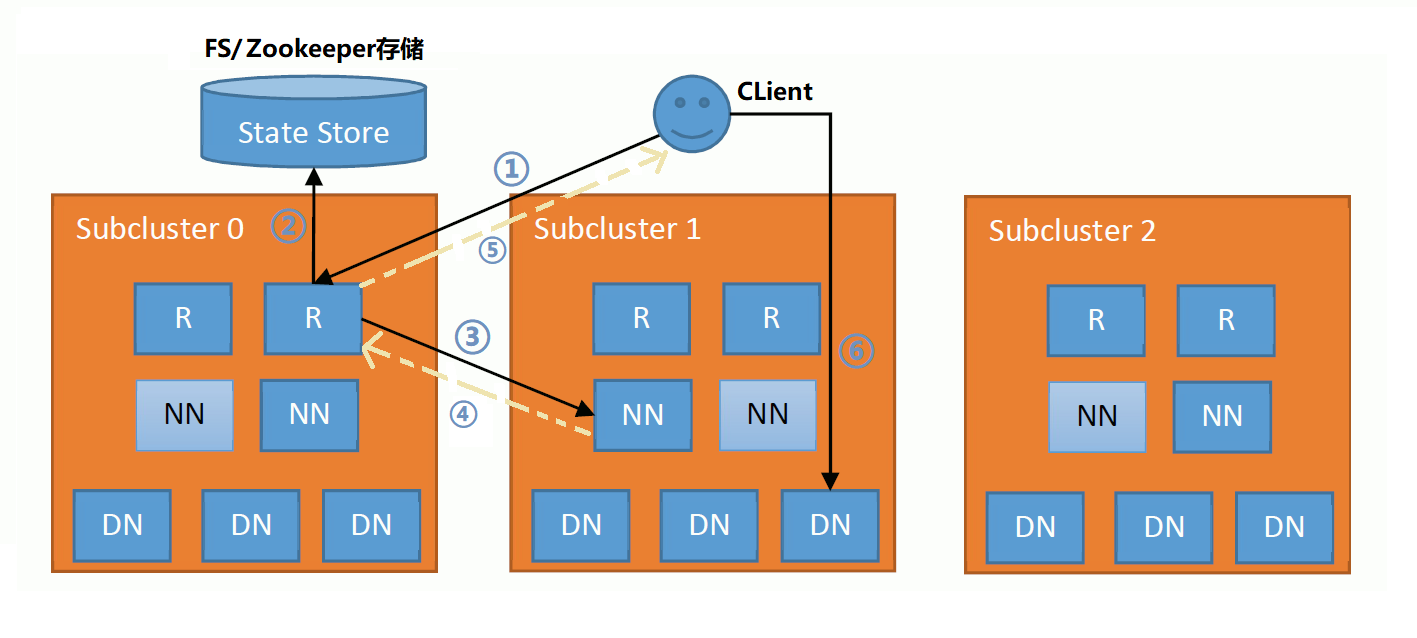
라우터는 네임노드나 데이터노드와 같은 데몬입니다. 공식적으로 subcluster에 함께 배치되도록 권장됩니다. 라우터는 데이터를 직접 저장하지는 않고 클라이언트의 요청이 들어오면 State store에서 매핑 정보를 쿼리하고 해당되는 네임노드에 이를 전달합니다. 그리고 네임노드로부터 데이터를 받아 이를 클라이언트에게 다시 전달해 줍니다. 평소에는 네임노드는 라우터에게 정기적으로 heartbeat를 보내 자신의 상태와 기본정보들을 알리고 라우터는 이를 받아 State store에 하트비트를 보냅니다.
기본 포트 변경
Hadoop 3.0 이전에는 많은 Hadoop 서비스의 기본 포트가 Linux 임시 포트 범위(32768-61000)였습니다. 이로 인해 이러한 서비스는 시작시 다른 응용 프로그램과 충돌하여 바인딩되지 않는 경우가 많았습니다. 따라서 하둡 3.0부터 HDFS의 구성요소들의 기본 포트 번호가 변경되었습니다.

Reference
Introduction to HDFS Erasure Coding in Apache Hadoop - Cloudera Blog
HDFS Erasure Coding in Action (slideshare.net)
HDFS Erasure Coding in Big Data Hadoop - An Introduction - DataFlair (data-flair.training)
| [Hadoop 3 | What’s New in Hadoop 3.0 Hadoop 3 Enhancements Edureka](https://www.edureka.co/blog/hadoop-3/) |
업그레이드를 부르는 Hadoop 3.0 신규 기능 살펴보기 Popit
Evaluation of Erasure Coding in Hadoop 3 Databases at CERN blog
대규모 스토리지에서 HDFS Erasure Coding을 사용할 때의 기술적 과제 - 2021 Korean version - - YouTube
Hadoop 3에서 Erasure Coding이란 - 2 (tistory.com)
Hadoop 3.x 버전의 Erasure Coding 설명 :: 눈가락★ (tistory.com)